- sequential model들의 발전 흐름과 동작 개념을 간략하게 알아본다.
Naive sequence model
- p(x_t | x_{t-1}, x_{t-2}, ...)
- 이전 입력들이 주어졌을 때 다음에 나올 데이터의 확률을 구한다.
Autoregressive model
- p(x_t | x_{t-1}, x_{t-2}, ..., x_{t-r})
- 매 순간 모든 입력을 조건으로 주면 계산이 힘드니 past timespan을 고정한다.
Markov model (first-order autoregressive model)
- p(x_1, ...., x_t) = p(x_t | x_{t-1}) * p(x_{t-1} | x_{t-2}) * ... * p(x_2 | x_1) * p(x_1)
- 현재는 바로 전 과거 딱 1개의 정보에 근거한다고 가정하고 확률을 구한다.
Latent autoregressive model
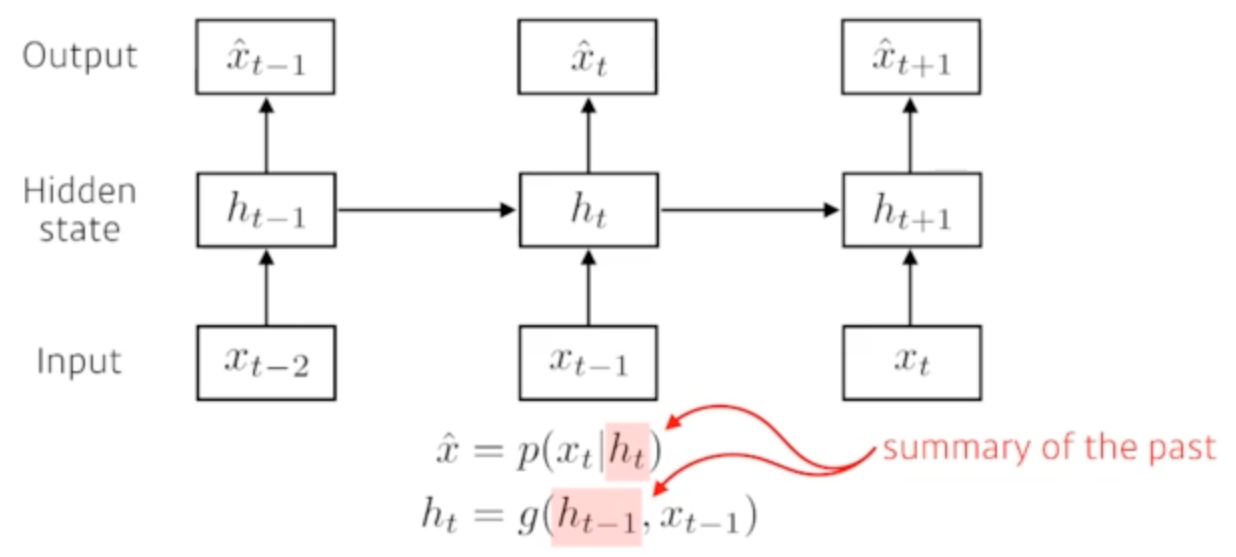
- x^ = p(x_t | h_t)
- h_t = g(h_{t-1}, x_{t-1})
- 모든 과거 정보를 고려하기는 어렵고 그렇다고 고정된 몇개에 의존하지 않는다.
- 과거의 정보들을 summarize하는 하나의 latent vector를 hidden state라고 부르고 이를 활용한다.
Recurrent Neural Network
Recurrent Neural Networks
- sequence data(소리, 문자열, 주가 등)는 순서가 중요 - sequence 데이터는 i.i.d(독립동일분포)를 위반하기 쉽다. - 개가 사람을 물었다. 사람을 개가 물었다. 이렇게 순서만 바꾸더라도 sequence data의 확
jsdysw.tistory.com
- short-term 정보는 잘 기억하지만 long term 정보는 잘 기억하지 못 하는 문제가 있다. (vanishing / exploding gradient)
Long Short Term Momory

- rnn에서 hidden state 하나만 이전 시점에서 받아오는 것과 달리 lstm에서는 x를 제외하면 previous cell state, previous hidden state 두 개가 입력으로 들어온다.
- 그림에 보이는 x 세개는 각각 왼쪽부터 순서대로 forget gate, input gate, output gate이다.
- previous cell state는 내부에서만 흐르는 latent vector이다. 이제까지 봤던 정보들을 함축해서 가지고 있다. forget gate, input gate를 거치면서 어떤 정보를 버리고 저장할지 판단해서 cell을 update한다.

- 마지막에 취합된 cell state가 output gate를 거칠때는 한번 더 조작해서 output으로는 뭘 내보낼지 결정한다. output이 hidden state이다.
- 즉 정리하면 이전 함축 정보를 단순히 squash하는게 아니라 버리고 보강하는 과정을 거쳐서 활용한다.
Gate Recurrent Unit

- cell state가 없다 hidden state가 곧 output이면서 다음 셀에 전달되는 정보이다.
- gate도 reset gate, update gate 두 개밖에 없다
- lstm보다 가벼우면서도 비슷한 혹은 조금 더 나은 성능을 보이는 경우가 있다고 한다.
'boostcamp AI tech > boostcamp AI' 카테고리의 다른 글
| Short history of Generative model (0) | 2023.11.24 |
|---|---|
| Transformer (2) | 2023.11.23 |
| Short History of Detection Model (0) | 2023.11.22 |
| Short History of Semantic Segmentation (1) | 2023.11.22 |
| AlexNet, VGGNet, GoogleLeNet, ResNet, DenseNet (2) | 2023.11.22 |



