The Illustrated Transformer
Discussions: Hacker News (65 points, 4 comments), Reddit r/MachineLearning (29 points, 3 comments) Translations: Arabic, Chinese (Simplified) 1, Chinese (Simplified) 2, French 1, French 2, Italian, Japanese, Korean, Persian, Russian, Spanish 1, Spanish 2,
jalammar.github.io
- 너무 중요하기 때문에 attention is all you need 논문 리뷰에서 자세히 추가로 다뤄보겠다.
- 지금은 brief understanding을 목표로 한다.
- 기존 rnn같은 sequential model들은 재귀적인 구조를 띄었다.
- transformer는 attention만을 활용해서 이런 구조를 완전히 버렸다.
- transformer는 이미지 detection, 생성 분류, 번역 할것 없이 활용되고 있다.

- rnn encoder-decoder가 세 단어로 구성된 문장을 입력으로 받는다고 하면 세번 돈다.
- 하지만 transformer는 100개든 1000개든 한번에 n개의 단어를 encoding한다.
1. 어떻게 한번에 encoding이 가능한가? Self-Attention

- self-attention을 통해 각각의 embedding vector x를 주변 단어를 고려한 새로운 정보 z로 변환한다.
- 그 이후 각 z들은 독립적으로 feed forward를 거쳐서 나간다.

- 우측 문장의 의미를 정확히 알려면 It이 뭘 가리키는지 알아야 한다. 즉 앞에 혹은 뒤에 단어들 중에서 누구랑 가장 관련이 높은지를 모델이 학습해야 한다. (attention)

- input 단어마다 q, k, v 벡터를 생성한다.
- thinking의 관점에서, query를 다른 모든 단어들에게 날린다. 이 말은 다른 단어들의 key vector와 thinking의 query vector의 interaction 정도를 dot product로 구한다는 말이다. 이게 곧 attention score이다.
- score값이 너무 커지지 않도록 조절하고 attention distribution으로 바꾼다. 이 분포가 attention weight가 된다.
- 각 attention weight를 각 values vector에 곱한다. '해당 v를 얼마나 관심있게 보면 좋을지'를 반영하는 셈이다.
- 그 value값들을 다 더해서 Z를 만든다. 이게 encoding의 결과 값이다.

- 이 말로 설명한 과정을 matrix연산식으로 다시 복습해보자. 위 그림에서는 두개의 단어로 구성된 시퀀스 X를 받는다.

- 이렇게 간단하게 표현이 된다.
- transformer는 input 데이터나 network구조가 fix되어있다고 하더라도 단어들 끼리의 연관성에 따라서 encoding값이 바뀐다. 훨씬 자유롭게 input의 관계를 학습할 수 있다.
- rnn은 1000개의 단어로 이루어진 문장이라고 하더라도 1000번 돌리면 되었다. 하지만 transformer는 1000개의 단어를 한번에 처리한다고 했다. 이를 위해 1000*1000의 attention map을 만들어야 하므로 상당히 메모리를 많이 잡아먹는다.
2. Multi-head attention (1)
- 앞서 우리가 이해한 attention을 여러번 반복한다.

- 이전에는 인풋으로 들어온 임베딩 벡터 하나에 대해서 한개씩의 q,k,v를 만들어 냈다. 이걸 여러개 만들겠다는거다. 그림에서는 head=8개의 q,k,v쌍들을 만들었다.
- 그럼 총 z도 8개가 만들어질 것이다. 그런데 다음 encoder로 들어가려면 크기를 embeding vector의 크기로 만들어줘야 한다.
- 이 차원 축소를 위해서 z0, ..., z7을 이어 붙여서 (2,24) tensor로 만든다음 linear transform해서 Z크기로 맞춘다.
3. Multi-head attention (2)
- 실제 multi-head attention을 보면 앞서 설명한 것처럼 구현되어있지는 않다.
- embedding vector가 100차원이라고 해보자. 10개의 Head를 사용한다고 하면 앞서 설명한 방법처럼 100차원 벡터에 대해서 q,k,v 10개를 만들지 않는다.
- 100차원의 embedding vector를 sub vector(10,) 10개로 나누고 쪼개진 sub vector들을 가지고 10번 q,k,v를 만든다.
- 그럼 이전 설명과 달리 축소하는 작업이 필요없다.
4. Positional encoding
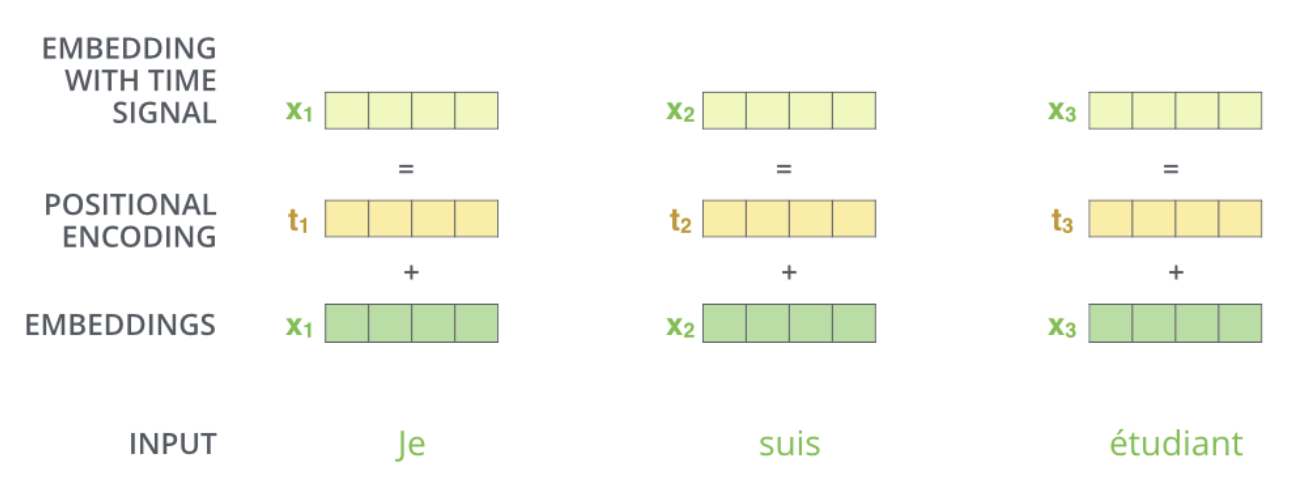
- a, b, c를 넣으나 c, b, a를 넣으나 각각의 input 단어가 encoding된 값은 변하지 않는다. input 이 순서가 있다고 하더라도 transformer 구조 자체가 order에 independent하기 때문이다.
- 문장을 구성할때는 어떤 단어가 먼저 나오냐 뒤에 나오냐도 중요하기 때문에 encoding된 값에 일종의 offset인 positional encoding 값을 더해준다.
- 저 Position encoding 값은 따로 만드는 방법이 있다.
5. Decoder

- 인코더는 주어진 단어를 표현하는 단계였다. 이제 decoder에서 어떤 값이 어디로 어떻게 전달되는지 결국엔 예측을 어떻게 하는지 살펴본다.
- 인코더의 제일 마지막 층에서 만든 K, V를 decoder에게 넘겨준다.

- decoder의 첫번째 self-attention layer에는 masking이라는 기법을 추가한다.
- attention은 앞, 뒤 할 것 없이 모든 단어들과의 관련도를 찾는다. 그런데 decoder가 i번째 단어를 생성해 낼 때 이후 단어들까지 알고있어 버리면 안되니까 masking으로 뒷 부분을 다 가려서 못 보도록 한다. 이전 단어들에 대한 dependency만 보도록 한다.
- 학습할 때도 inference할 때도 똑같이 masking을 적용한다.
- encdoer-decoder attention 층에도 작은 변화가 있다.
- 바로 이전 layer에서 받은 값들만 가지고 Queries matrix를 만들고 K, V는 encoder 마지막 층에서 가져온다.
- 이 Q, K, V를 가지고 똑같이 attention을 수행한다.

- 최종 결과값을 가지고 vocab_size만큼의 distribution으로 변환하여 제일 확률이 높은 단어를 뱉는다.
'boostcamp AI tech > boostcamp AI' 카테고리의 다른 글
| Naive-Bayse Classifier (1) | 2023.11.27 |
|---|---|
| Short history of Generative model (0) | 2023.11.24 |
| Short History of Sequential Model (1) | 2023.11.23 |
| Short History of Detection Model (0) | 2023.11.22 |
| Short History of Semantic Segmentation (1) | 2023.11.22 |


