- 이제까지 봤던 image classification과는 다른 segmentation task의 문제들을 AI가 어떻게 풀고 있는지 살펴본다.
- semantic segmentation model들의 발전 흐름과 동작 개념을 간략하게 알아본다.

- 각 픽셀들이 고양이에 속하는지 배경에 속하는지 분류한다고 생각하면 된다.
1. Convolutionalization

- 우리가 보통 떠올리는 이미지 분류 문제를 푸는 모델은 이렇게 생겼다. 맨 마지막에 dense layer를 통해 flatten한 input을 label 수만큼의 차원으로 바꿔준다.
- (4,4,16)을 flatten시키면 dense layer의 input tensor의 길이는 256이 된다. label이 10개라면 총 파라미터 수는 2560개 이다.(bias제외, 커널크기 (4,4))

- desne layer를 없애고 conv만으로 똑같은 output을 만들어내는 방식을 convolutionalization이라고 한다.
- (4,4,16)을 바로 label 10개로 만들기 위해서는 4*4*16*10=2560개의 파라미터가 필요하다.(bias제외, 커널크기 (4,4))
- 파라미터 수는 dense layer를 사용할 때랑 달라지지 않았다.
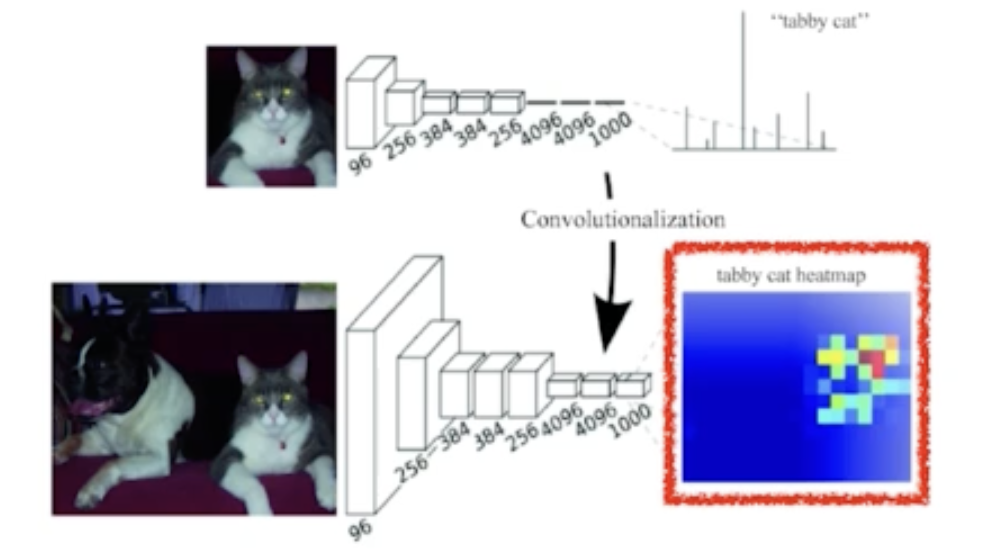
- 그럼 왜 멀쩡한 desne layer를 두고 convolutionalization을 했을까?
- semantic segmentation관점에서 바라보면 얻는 이득이 있다.
- linear layer에서는 이미지를 flatten시키고 계산하기 때문에 이미지의 spatial 한 정보들을 다 잃어버린다.
- 반면 convolution은 계속해서 사각형만 작아지지 위치정보를 그대로 가져간다.
- 즉 최종결과는 이미지에서 고양의 위치를 유추하게 해주는 heatmap을 내보내는 셈이다.
- 또 linear layer를 사용하면 모델이 받는 Input의 크기가 고정된다. (linear layer의 input, output사이즈를 고정해야하기 때문)
- 반면에 cnn은 parameter를 계속 share하면서 이미지가 크던 작던 훓고 가기때문에 입력 이미지의 크기로부터 자유롭다.
2. Deconvolution
- 이제 convolutionalization을 수행했다. 그러나 ouput은 input대비 크기가 예를들어 (10,10)으로 줄어들어버렸다.
- output (10,10)에서 하나의 픽셀이 input에서 바라보고 온 영역이 상당히 크다. coarse하다고 한다.
- 그러니 이 output을 dense map으로 키워줄 필요가 있다 (input크기 까지는 아니여도 최대한 크게)
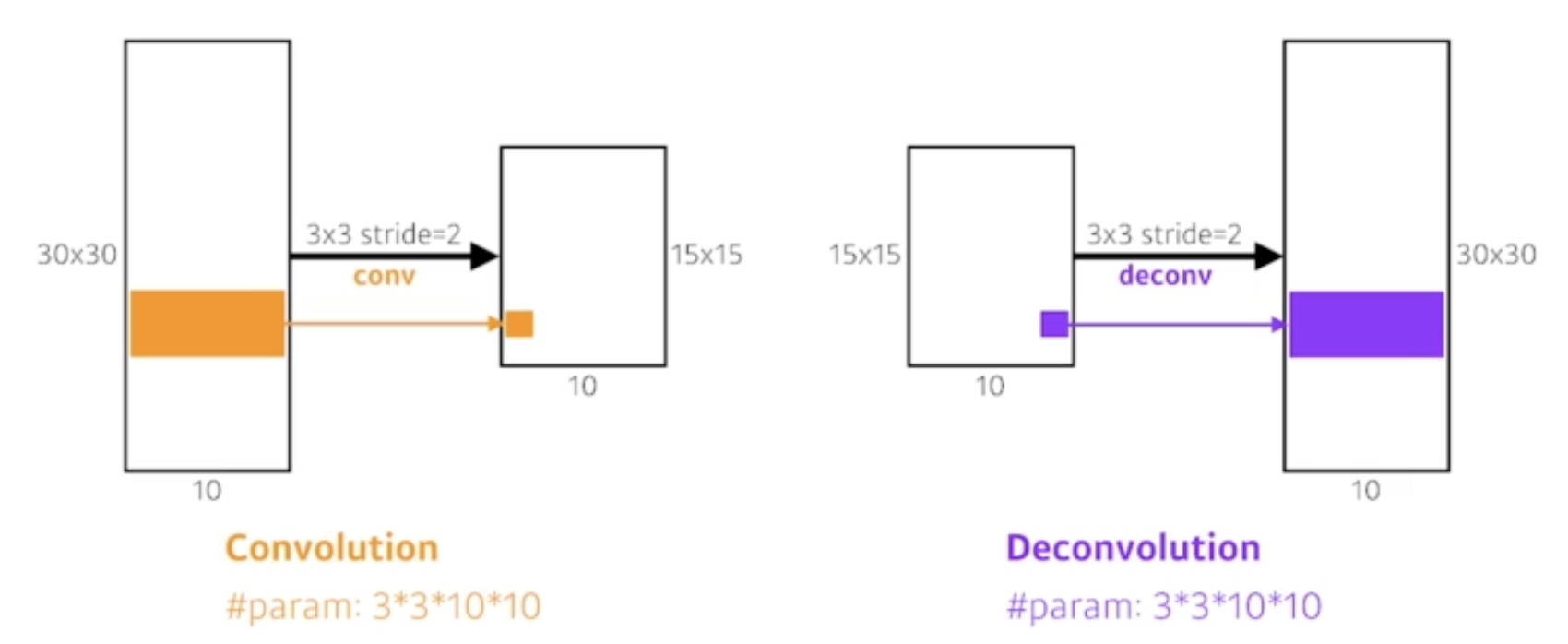
- 그래서 convolution의 transpose에 해당하는 연산이 필요하다. 하지만 convolution은 여러 정보를 받아서 하나만 뱉어내는데 이게 말이 되는것 같지 않다.
- 그래서 input에 padding을 충분히 주고 결국은 원하는 크기로 convolution하는 방법으로 복원한다.
- 편의상 deconvolution, convolution transpose라고 한다.
- 참고로 computer graphics에서 많이 사용하는 Bilinear Interpolation으로 값을 복원할 수도 있다.
'boostcamp AI tech > boostcamp AI' 카테고리의 다른 글
| Short History of Sequential Model (1) | 2023.11.23 |
|---|---|
| Short History of Detection Model (0) | 2023.11.22 |
| AlexNet, VGGNet, GoogleLeNet, ResNet, DenseNet (2) | 2023.11.22 |
| Regularization (1) | 2023.11.21 |
| Optimization (2) | 2023.11.21 |



