- semantic segmentation이 픽셀을 객체의 일부분으로 분류한다면 detection은 객체의 bounding box를 찾는 문제이다.
- detection model들의 발전 흐름과 동작 개념을 간략하게 알아본다.
1. R-CNN
- 가장 간단한 방법으로 R-CNN이 있다.
- input image에서 특정 알고리즘을 통해 예를들어 2000개의 patch를 뽑아낸 다음 (물론 크기를 맞추기위해 crop,resize도 필요하다) CNN layer를 거치게 하여 feature를 뽑아낸다. 이 feature들로 사람이니? 고양이니? 나무니?를 SVM으로 분류하는 것이다.
- 그럼 input이미지에서 object의 위치를 잡을 수 있을 것이다.
- 가장 간단한 만큼 문제가 있다. 2000개의 patch를 뽑았으면 cnn layer를 2000번 통과시켜야 한다.
2. SPPNet
- 매번 patch 수만큼 돌리는건 매우 비효율적이고 느리기 때문에 input이미지가 왔을때 딱 한번 CNN으로 feature map들을 뽑는다.
- 그 이후 patch들 2000개를 고른 후, 이미 계산해두었던 feature map에서 patch에 해당하는 tensor들만 가지고 온다.
- 이러면 patch별로 feature map을 만들 수 있고 (CNN계산은 처음 딱 한번 함) 이 feaure map을 SVM에게 분류하라고 시킨다.
- 방법은 R-CNN과 똑같다 다만 CNN layer는 한번만 돌린다.
3. Fast R-CNN
- SPPNet과 똑같다.
- selective search를 통해 2000개의 patch를 뽑고 (2000개의 patch를 뽑는다는 말은 2000개의 bounding box후보들을 뽑는 것이다)
- input 이미지를 CNN층에 한번 통과해서 feature map을 구하고
- feature map으로부터 ROI pooling을 통해 region별 fixed feature map을 구한다. (이미 구한 feature map에서 해당하는 부분만 가져온다)
- 여기서 spp-net과 차이가 나오는데, 뒷단을 neural network로 교체했다.
4. Faster R-CNN
- 이제는 region을 뽑아내는 일도 학습에 맡긴다.

- Region Proposal Network로 2000개씩 임의로 patch들을 선택했던 역할을 대신한다.
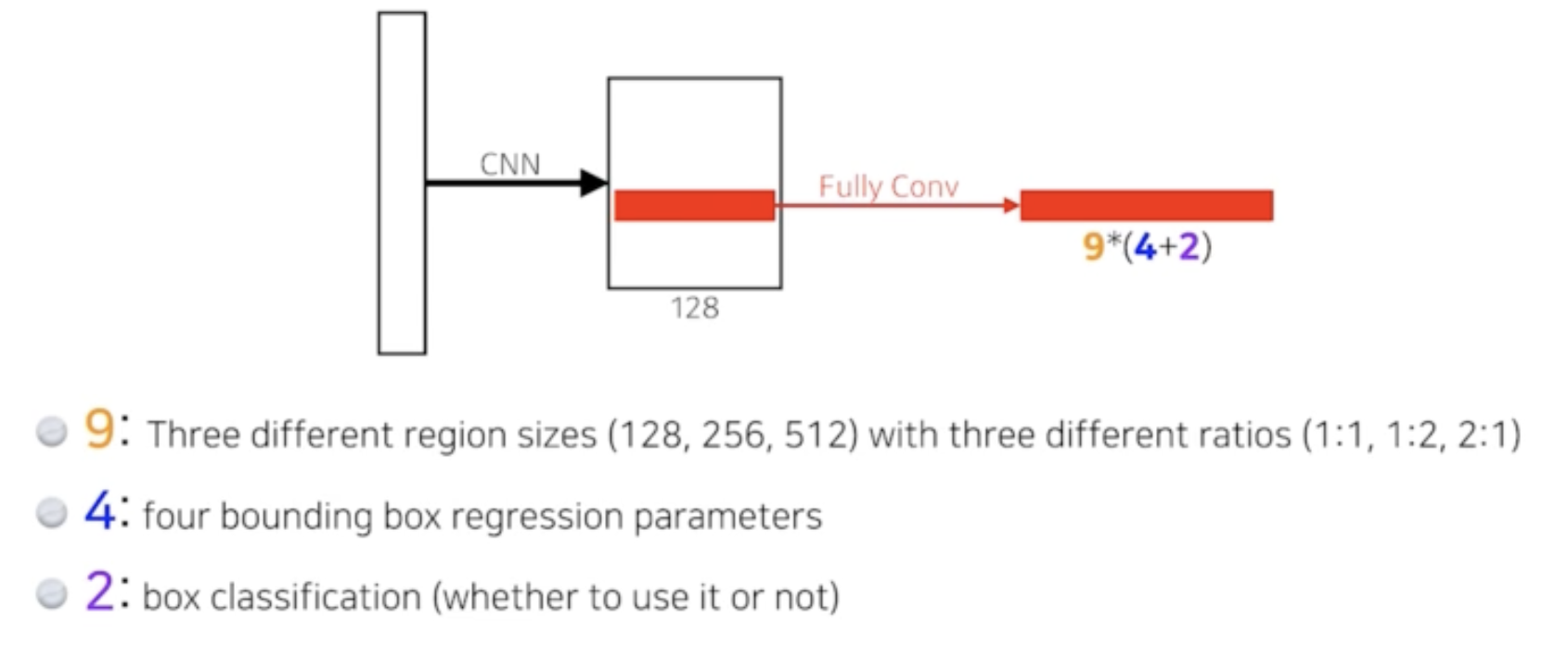
- input이미지를 계속해서 cnn을 거치게하여 작게 만들면 그 feature map의 한 칸은 receptive field의 정보를 함축하고 있다고 볼 수 있다.
- feature map의 한칸을 중심으로 미리 정해 둔 anchor boxes 들에 물체가 있는지 없는지를 RPN이 판단한다.
- anchor box의 조합 9개와 그 box의 크기를 조절하는 파라미터 4개, 이 박스가 쓸모 있는지 없는지를 위한 2개의 파라미터를 가지는 정보를 도출한다.
- 이렇게 얻은 region proposal 정보와 그 region에 해당하는 feature map을 가지고 뒤에 있는 classifier가 사람 혹은 자동차인지 아닌지를 판단한다.
- 드디어 end-to-end object detection이 가능해졌다.
5. YOLO
- 굉장히 빠른 속도의 object detection이다.
- 훨씬 빠른 속도의 비결은 region proposal을 통해 분류한 결과를 가지고 다시 분류하지 않고 한방에 한다는 점에 있다. (You Only Look Once)

- 이미지가 들어오면 S*S개의 grid cell로 나눈다.
- 가장 먼저 grid cell별로 B개 만큼의 x,y, width, height를 예측하게 한다. (=B개의 bounding box를 예측) 그럼 한장의 input image에 대해 B*S*S 의 bounding box를 예측한다.
- 이 bounding box에 물체가 있을 확률, 쓸모 있는지 없는지를 예측하게 한다.(= confidence)
- 이와 동시에 그리드 셀들의 classification을 한다.(개, 자전거, 차)
- 이 두 정보를 취합하면 박스와 그 박스의 class를 알 수 있다.
- 즉 최종적으로 S*S*(B*5+C)의 tensor를 얻을 수 있다.
- B개의 box, 5가지 정보(x,y,width,height,confidence), class 수
- 끝으로 detection을 위한 아이디어가 진화화는 과정에 초점을 두기위해 자세한 테크닉과 구현내용은 생략하였다. 더 궁금하다면 해당 논문들을 살펴보자
'boostcamp AI tech > boostcamp AI' 카테고리의 다른 글
| Transformer (2) | 2023.11.23 |
|---|---|
| Short History of Sequential Model (1) | 2023.11.23 |
| Short History of Semantic Segmentation (1) | 2023.11.22 |
| AlexNet, VGGNet, GoogleLeNet, ResNet, DenseNet (2) | 2023.11.22 |
| Regularization (1) | 2023.11.21 |



