Neural Machine Translation by Jointly Learning to Align and Translate
Neural machine translation is a recently proposed approach to machine translation. Unlike the traditional statistical machine translation, the neural machine translation aims at building a single neural network that can be jointly tuned to maximize the tra
arxiv.org
Abstraction
seq2seq에서는 Encoder가 문장을 입력받아서 fixed length context vector를 만들어내면 decoder는 이를 가지고 번역 문장을 생성해 낸다.
본 논문에서는 이 fixed length context vector가 성능 향상에 있어서 bottleneck이라고 보았다. 실제로 encoder-decoder 모델들을 보면 training corpus보다 긴 문장을 실제로 마주했을 때 급격한 성능하락을 보였다.
그래서 매 timestep t마다 output을 예측할 때, source sentence에서 가장 relevent한 부분을 고려하도록 encoder-decoder를 확장했다.
decoder가 t시점에서 예측을 수행할 때 아래 세가지 값을 사용한다.
1. set of positions in a source sentence where the most relevant information is concentrated (context vector)
2. previous generated target words
3. previous hidden state
1번은 seq2seq에서 사용했던 context vector와는 완전히 다른 정보이다. 더 이상 encoder가 전체 Input을 하나의 벡터로 만들지 않는다는게 핵심이다. 대신 encoder는 input을 받아서 a sequence of vectors를 매 시점에 거쳐서 만들어 낼 것이다.
decoder는 매 시점마다 예측을 할때 adaptive하게 해당 vectors들의 subset을 활용할 것이다.
이렇게 함으로써 긴 문장을 하나의 고정길이 벡터로 squash하지 않아도 되며 long sentence input 뿐만 아니라 어떤 길이의 input에 대해서도 더 좋은 성능을 얻을 수 있다.
이어서 Machine translation에 대한 background를 소개하고 attention이라는 새로운 아이디어를 제안하기 전에 이전의 RNN base encoder-decoder에 대해서 설명한다. (seq2seq 논문을 보면 이해하기 쉽다)
The Illustrated Transformer
Discussions: Hacker News (65 points, 4 comments), Reddit r/MachineLearning (29 points, 3 comments) Translations: Arabic, Chinese (Simplified) 1, Chinese (Simplified) 2, French 1, French 2, Italian, Japanese, Korean, Persian, Russian, Spanish 1, Spanish 2,
jalammar.github.io
15-01 어텐션 메커니즘 (Attention Mechanism)
앞서 배운 seq2seq 모델은 **인코더**에서 입력 시퀀스를 컨텍스트 벡터라는 하나의 고정된 크기의 벡터 표현으로 압축하고, **디코더**는 이 컨텍스트 벡터를 통해서 출력 …
wikidocs.net
*여기 아주 기가막히는 그림과 설명이 있으니 아래 논문 수식만으로 이해가 어렵다면 보고 돌아오자. 약간의 차이가 있지만 도움이 될 것 같다.
*아래 메커니즘을 이해하고나면 이 모든 설명이 명쾌해 질 것이다.
자 그래서 본 논문에서 새로운 architecture를 제안한다. 서두에 먼저 요약을 하면 bidirectional RNN을 encoder로 사용하고 decoder는 source sentence에서 relevant한 부분을 search한다.
Decoder
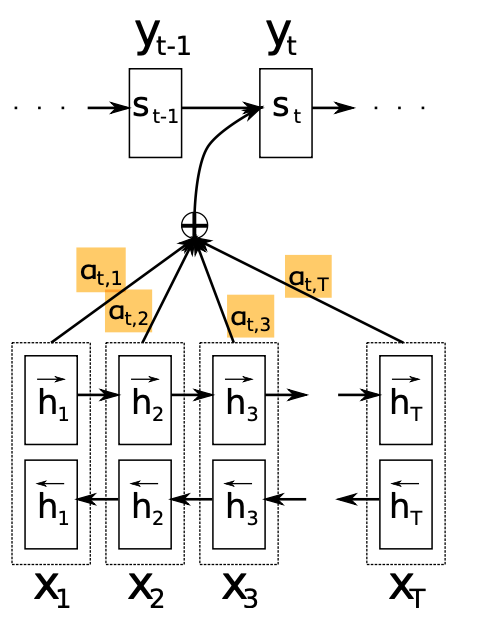
Input sequence X = {X_1, X_2, ..., X_t} 에 대해서 매 시점 t마다 hidden state 들이 있다. {h_1, h_2, ..., h_t}
h_i는 input sequence를 전부 고려하면서도 i번째 단어 주변에 특히 집중하는 정보라고 볼 수 있다.
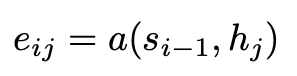
먼저 enery_ij를 살펴보자. decoder가 i번째에 token을 예측할때는 이전 hidden state, s_{i-1}을 활용한다. 따라서 e_ij는 decoder가 i번째의 token을 예측을 할 때 s_{i-1}과 encoder의 j번째 hidden state가(hj) 얼마나 관련이 높은가? 를 scalar로 계산하는 일종의 (attention) score이다.
저 함수 a는 parametrize가 가능한 alignment model이다. 어떤 방식으로 두 벡터의 유사도를 계산하여 score를 도출할지는 다양한 변형이 있을 수 있다. 중요한 점은 alignment model이 backpropagation을 통해 학습이 가능한 부분이라는 것이다. (latent variable이 아님)
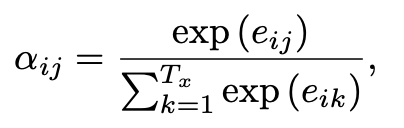
이 score들을 softmax를 거치도록 하여 probability로 만든다. (attention distribution)
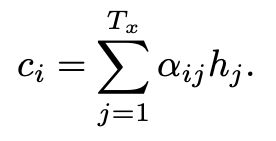
그럼 각 시점에서의 encoder hidden state hj에 우리가 구한 weight(attention score a_ij)을 곱한다. T개의 vector들을 모두 더해서 i 시점에서의 context vector를 만든다.(weighted sum of all the annotations)
이것이 바로 set of positions in a source sentence where the most relevant information is concentrated (context vector, attention value)이다. decoder가 i시점에서 출력을 할 때, input sequence의 어느 위치 정보가 가장 relevant한지를 반영한 것이다.
다시말하면 decoder가 i시점에 예측하는 target, yi가 input, xj로부터 어느정도 관련도를 갖는가?를 계산한 것이 a_ij인 셈이다.
그럼 decoder가 prediction을 할 때, 모든 시점의 입력값들을 고려하면서도 그중에서 가장 중요도가 높은 position은 특히 집중할 수 있게 된다.
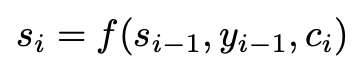
이 context vector(attention value)를 가지고 decoder가 s_t(결국엔 y_t)를 예측할 때 활용하는 것이다. decoder는 매 시점마다 ci를 구해서 사용한다.
f(previous hidden state, previous prediction, context vector)
어느 부분에 pay attention할것인지 매 시점마다 decoder가 결정한다.
Encoder
preceding words 뿐만 아니라 following words도 함께 고려하고자 BiRNN을 사용했다. 양방향 reading을 통해 생성된 두 h_j를 concat해서 h_j를 만든다. 이 h_j는 전체 sequence의 고려하면서도 특히 x_j 주변을 집중하는 정보라고 볼 수 있다.
Result
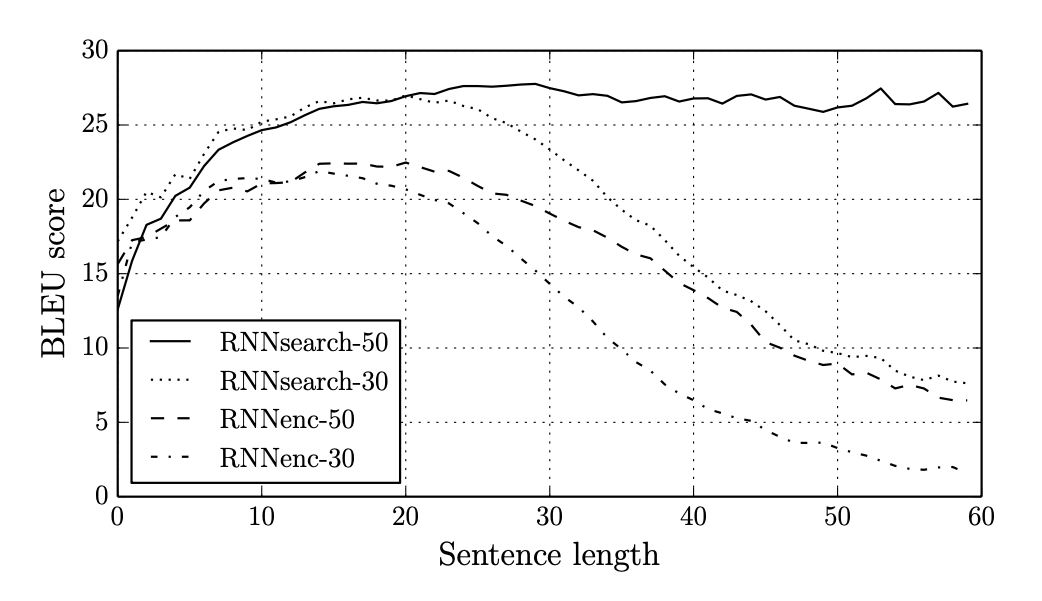
RNNsearch-50은 50개의 단어로 구성된 문장까지 학습한 attention 적용 모델이고 RNNenc-30은 30개의 단어로 구성된 문장까지 학습한 encoder-decoder 모델이다.
RNNenc모델은 encoder, decoder 각각 1000 hidden units 을 가지고 있고
RNNsearch의 encoder는 양방향이므로 합해서 총 2000 hidden units, decoder는 1000 hidden units를 가지고 있다.
둘다, decoder의 ouput은 multilayer network를 거쳐서 target word의 확률을 계산하도록 했다. 이후 beam search를 통해 최종 결과물을 만든다.
SGD, Adadelta, batch size, 학습 시간 등 최대한 비슷한 조건으로 모델을 훈련했다.
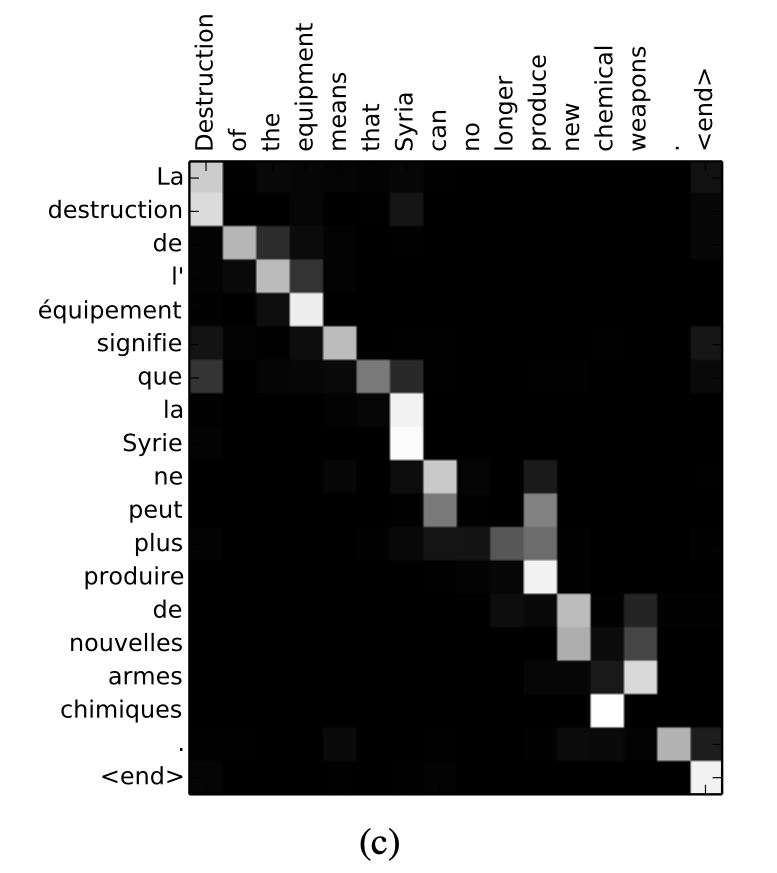
이 그림은 RNNsearch-50의 test sample을 가져온 것이다. i-th target word에 대해서 j-th source word의 annotation이 갖는 weight a_ij를 나타낸 그림이다.
영어와 불어가 monotonic하다는 점을 고려하면 diagonal을 따라서 강한 weight가 그려진다. 영어와 불어의 adjective, noun순서가 다른것을 고려하면 non-monotonic한 alignment도 있을 수 있는데 matrix를 보면 이 또한 잘 학습한 것으로 보인다. 단어 sequence를 점프한다던가 뒤를 고려하는 등의 모습도 보인다.
논문에서는 soft-alignment라고 한다. 예를들어 [the man] -> [l' homme] 로 번역 될 때, hard alignment는 [the] -> [l], [man] -> [homme]로 매핑하는데 반해, soft-alignment는 [the]뒤에 오는 단어에 따라 [le] [la] [les] [l']로 번역될 수 있음을 배워서 [the]와 [man] 모두를 고려한 번역을 한다. 이 점이 attention score가 빛을 발하는 대목이 아닐까 싶다.
게다가 서로 다른 길이의 번역 문장, input 문장에 대해서도 잘 한다고 설명한다.
End
이 논문은 encoder-decoder 구조에서 fixed length context vector를 문제라고 생각하고 attention mechanism을 추가해서 개선을 보였다. 끝으로 unknown, rare words에 대한 더 나은 handling을 도전과제로 시사하며 마친다.
훗날 이 엄청난 아이디어는 encoder-decoder구조를 버리고 transformer라는, 현 시대를 평정해버린 모델 architecture의 근간이 되었다.



