
Let's implement linear regression only using tensors including the data pipeline, model, loss, minibatch stochastic gradient descent optimizer.
- Generating Dataset
- Reading the dataset (minibatches)
- Initializing Model Parameters
- Defining the Model
- Defining the Loss Function
- Defining the Optimization algorithm
- Training
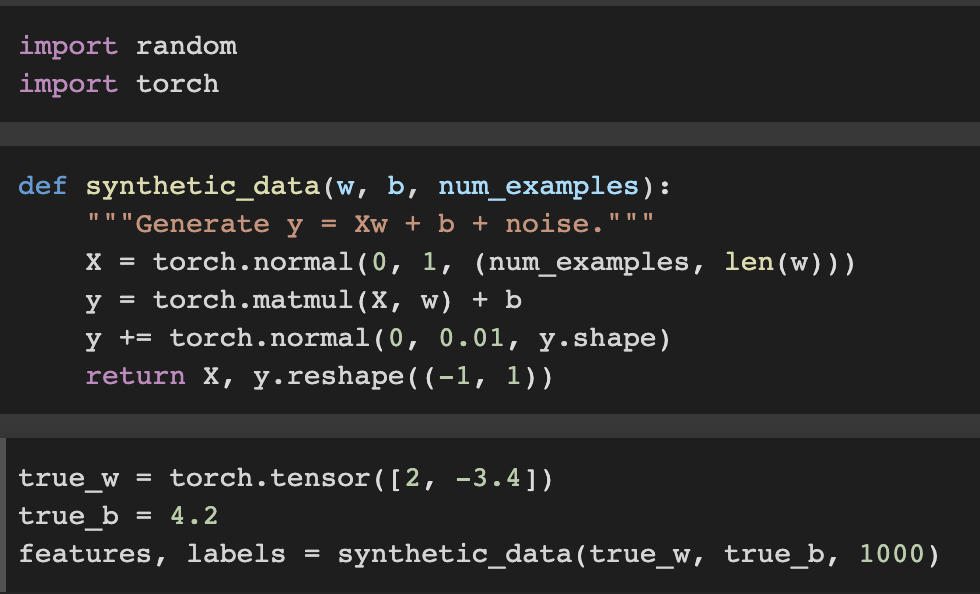
1. Generating Dataset
Our synthetic datset will be a matrix
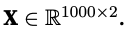
Our synthetic labels will be assigned according to the following linear model with the noise term ε
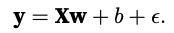
We will assume that ε obeys a normal distribution with mean of 0.

2. Reading the dataset (minibatches)
Using only these dataset we will find out the true_w, true_b with our models.
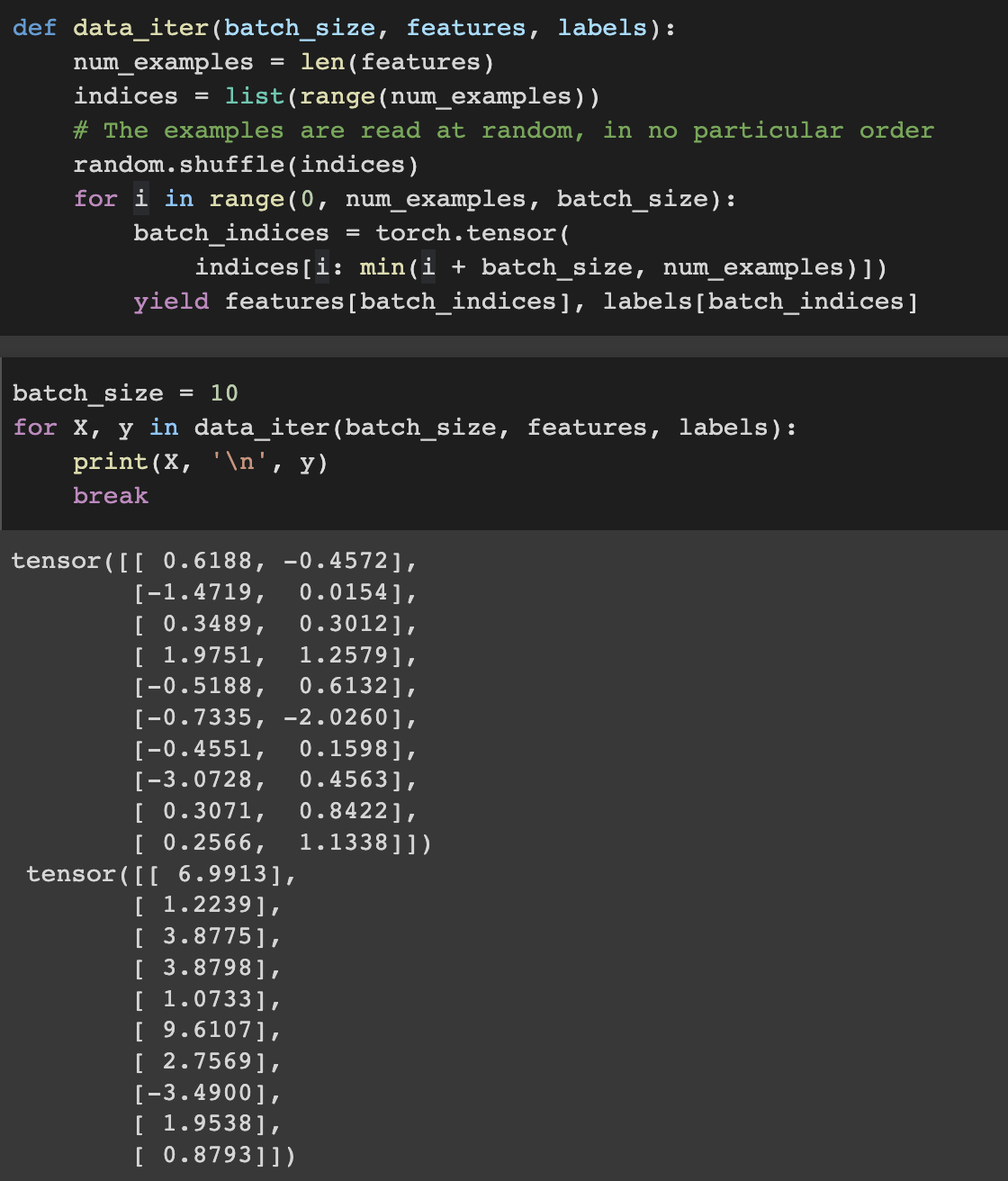
Now make several minibatches
As we run the iteration, we obtain distinct minibatches successively until the entire dataset has been exhausted
While this iteration implemented above is good for didactic purpose but it is inefficient because we load all the data in memeory. so use built-in iterators implemented in a deep learning framework which is considerably more efficient.
3. Initializing Model parameters
initialize weights by sampling random numbers from a normal distribution with mean 0 and a standard deviation of 0.01, and setting the bias to 0.

4. Defining the Model
It's a simple linear regression model so we simply take the matrix-vector dot product of the input features X and the model weights w, and add the offset b to each example

5. Defining the loss function

Updating our model requires taking the gradient of our loss function, we ought to define the loss function. y_hat is the prediction and y is the label.
6. Defining the optimization algorithm

At each step, using one minibatch randomly drawn from our dataset, we will estimate the gradient of the loss with respect to our parameters.
The size of the update step is determined by the learning rate lr. Because our loss is calculated as a sum over the minibatch of examples, we normalize our step size by the batch size (batch_size),
7. Training
In each iteration(epoch), we will grab a minibatch of training examples, and pass them through our model to obtain a set of predictions. After calculating the loss, we initiate the backwards pass through the network, storing the gradients with respect to each parameter. Finally, we will call the optimization algorithm sgd to update the model parameters.
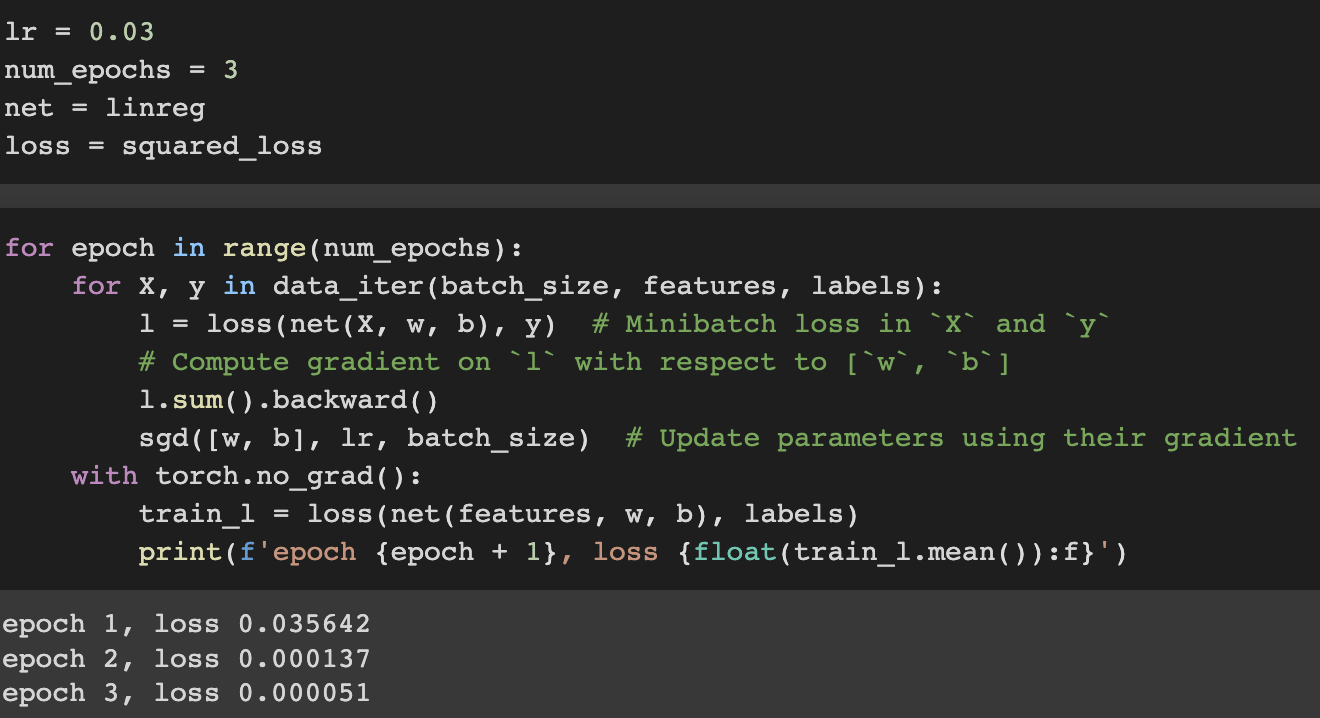

In deep learing we are typically less conerned with finding a perfect answer more concerned with parameters that lead to highly accurate prediction.
'ComputerScience > Machine Learning' 카테고리의 다른 글
| Deep Learning - 2.4 Softmax Regression (0) | 2022.08.18 |
|---|---|
| Deep Learning - 2.3 Concise Implementation of Linear Regression (0) | 2022.08.16 |
| Deep Learning - 2.1 Linear Regression (0) | 2022.08.11 |
| Deep Learning - 1.6 Probability (0) | 2022.08.09 |
| Deep Learning - 1.5 Automatic Differentiation (0) | 2022.08.06 |



