Investigating Decoder-only Large Language Models for Speech-to-text Translation
Large language models (LLMs), known for their exceptional reasoning capabilities, generalizability, and fluency across diverse domains, present a promising avenue for enhancing speech-related tasks. In this paper, we focus on integrating decoder-only LLMs
arxiv.org
0 Abstract
integrate decoder-only LLMs to the task of speech-to-text translation (S2TT)
propose a decoder-only architecture that enables the LLM to directly consume the encoded (continuous, not discretized tokens) speech representation and generate the text translation (adapts a decoder-only LLM to the speech-to-text translation task)
Additionally, we investigate the effects of different parameter-efficient fine-tuning techniques and task formulation.
*continuous vs discretized
W2vBERT : it outputs a sequence of real-valued vectors that capture the details of the input speech without discretizing it.
AudioPaLM : For example, using methods like vector quantization, you might map a range of audio features to a specific finite set of discrete codes
1. Related Works
- Traditionally, S2TT has employed a cascaded architecture with separate automatic speech recognition (ASR) and machine translation (MT) components
- Emerging end-to-end (E2E) approach, which integrates audio encoding and text decoding into a single process, has gained popularity for the benefits of error propagation mitigation and latency reduction
- Multilingual end-to-end speech translation
- suffers from poor out-of-domain generalization and failure to capture nuanced details
- adapting LLMs to a specific speech or audio task.
- Speech-LLaMA
- AudioPaLM : adapt LLMs to speech by discretizing speech representations and treat the discrete tokens as additional text tokens.
- its performance is highly dependent on the quality of the speech encoder
- the discretization makes finetuning the speech encoder hard, which requires fine-tuning the speech encoder with ASR first
- Our paper demonstrates that using continuous speech representations mitigates these issues, achieving better performance while being simpler.
2.1 Task Formulations
- f : S -> Y
- S : source speech input
- Y : target translation Y = {y1, y2, ... , yM)
- f_chain : S -> {Y_ASR, Y}
- Y_ASR : transcription of the source speech
- f_ASR : S -> Y_ASR
2.2 Architecture
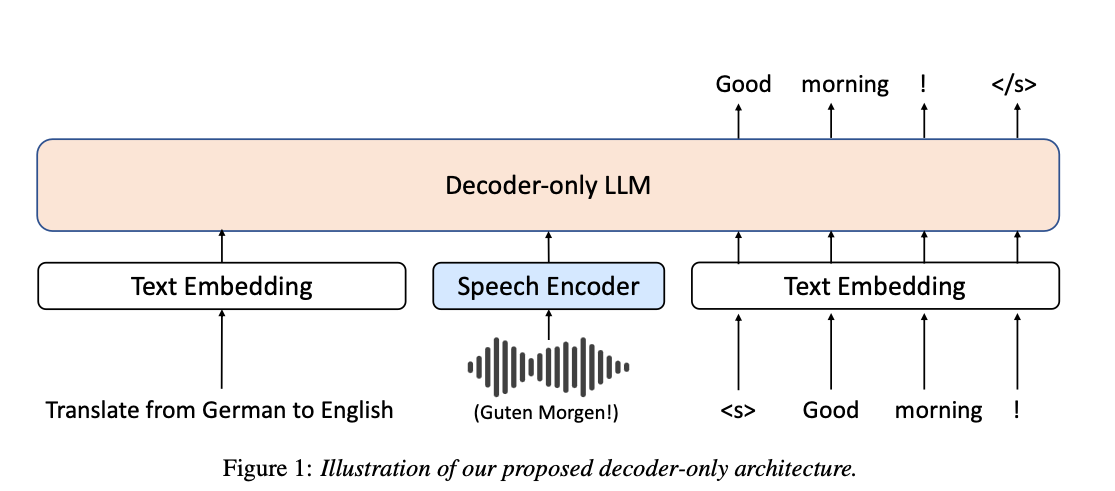
- speech encoder
- transformer architecture
- based on W2v-BERT, a self-supervised pre-trained speech encoder.
- speech input -> fbank features, F = {F1, ... , Fn}, where n denotes the sequence length of the fbank feature -> speech encoder, Es() -> hidden representation, Es(F)
- Speech frames are typically much more granular than text tokens.
- length adapter on top of the speech encoder to reduce the length of the speech representations
- 1-dimensional convolutional layer with a filter size and stride of k, which reduces the length of the speech representations by k-fold.
- text decoder
- based on LLaMA-2, a decoder only large language model
After encoding, the input sequence to the transformer decoder will be X = {Emb(X1),Es(F),Emb(X2)}
apply a linear transformation to the decoder outputs to obtain the logits for predicting the next token O = W⊤D(X), where D denotes the transformer decoder
2.3 Training
To let our model distinguish among tasks, we provide different instructions in natural language for each task t. The instructions include a description of the task, the source language, and the target language.

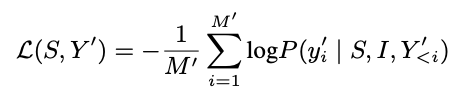
3.3 Parameter-efficient Fine-tuning
computationally expensive and inefficient to fine-tune all of the parameters during training
It is common to apply parameter-efficient fine-tuning techniques when fine-tuning LLMs on downstream tasks to improve efficiency and mitigate catastrophic forgetting
3.3.1 LayerNorm and Attention(LNA) Fine-tuning
fine-tune only the layer normalization and the self-attention layers in the transformer decoder
greatly reduces the number of trainable parameters during fine-tuning and avoids catastrophic forgetting,
thus improving the downstream performance for multilingual speech-to-text translation
3.3.2 Low Rank Adaptation(LoRA)
LoRA injects trainable rank decomposition matrices into the projections layers of a transformer model, which serves as a residual path in addition to a projection layer.
During fine-tuning, only the decomposition matrices are updated, while all of the pretrained parameters are frozen
The decomposition matrices can be merged into the original projection matrix after fine-tuning.
Therefore, there is no additional computation nor additional parameters compared to the pretrained transformer models during inference.
4. Experiments
During training, the effective batch size is set to 800K speech frames, or 8000 seconds of speech inputs.
We fine-tune all parameters of the speech encoder and apply parameter-efficient fine-tuning methods to the text decoder.


compare our decoder-only architecture with encoder-decoder models, with NLLB and LLaMA-2 as the text decoder.
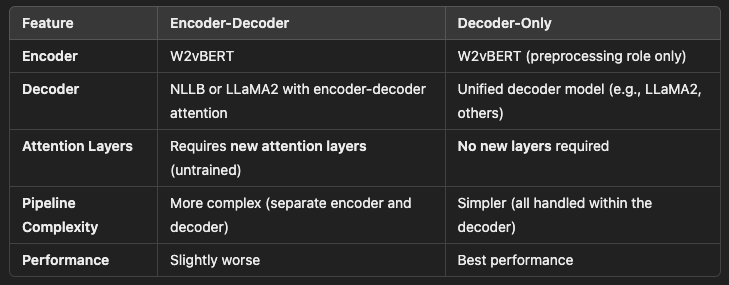
We hypothesize that it is the newly introduced encoder-decoder attention layers which are not pretrained that degrade the performance of encoder-decoder models.

freeze W2vBERT and fine-tune / freeze decoder and fine-tune / LoRA fine-tune / LNA fine-tune
freezing the speech encoder results in detrimental performance degradation. This result shows that fine-tuning the speech encoder is crucial for aligning the speech representation with the text inputs.

Notably, training with f and f_ASR slightly underperforms f , showing that multi-task training with ASR does not always improve performance.



