Feature Unlearning for Pre-trained GANs and VAEs
We tackle the problem of feature unlearning from a pre-trained image generative model: GANs and VAEs. Unlike a common unlearning task where an unlearning target is a subset of the training set, we aim to unlearn a specific feature, such as hairstyle from f
arxiv.org
0. Abstract
Feature unlearning is simply making a model to exclude the production of samples that exhibit target features.
Suggest a novel method of feature unlearning from pre-trained image generative models(GANs, VAEs)
- collect randomly generated images that contain the target features.
- then identify a latent representation corresponding to the target feature
- use the representation to fine-tune the pre-trained model.
1. Introduction
Concerns on recent advancement in deep generative model
- generated images may contain violent or explicit content
- inadvertently leak private information used to train the model
Common approaches
- models are trained with datasets which doesn't contain target features. (supervised)
- by removing entire image or target features
- pixel level supervision, specifying areas to unlearn (expensive)
This may lead loss of high fidelity and diversity of generated samples.
lose other details in the remaining region of the image.
worst case, what if training data is inaccesible?
2. Related Work
2.1 Former Approaches
- representation detachment approach to unlearn the specific attribute for the image classification task
- selectively remove sensitive attributes from latent feature space
- focus on supervised learning tasks.
- data redaction method from pre-trained GAN.
- use a data augmentation-based algorithm
- This method can only be applied when the entire dataset is available.
- Unlearning methods applicable to text-to-image diffusion models.
- limited to cross-attention-based models
We propose,
- Applicable to unsupervised generative tasks
- Works when the training dataset is not accesible
- Can be applied to any generative model that has its own latent space
2.2 Latent vector of target feature
GAN and VAEs well preserve the information of data within a low-dimensional space
Can obtain the visual feature vector by subtracting the two latent vectors
- (mean latent of the images without the features) - (mean latent of the images with the features)
3. Feature Unlearning for Generative Model
3.1. Dataset Preparation
First curate dataset
‘positive’ dataset : images that contain the feature to be erased from generated images.
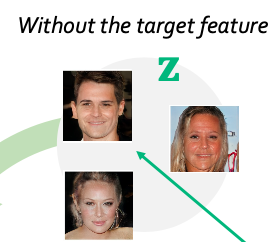
‘negative’ dataset : the rest of the images without the target feature from generated images

3.2. Target feature's latent respresentation
We assume that a vector in the latent space can represent the target feature.
Find a latent representation z_e that represents the target feature in the latent space.
- (mean latent of the images without the features) - (mean latent of the images with the features)
3.3. Sample a latent vector z from a simple distribution.
(3.a) If the latent vector z does not contain the target feature (z_e), let the generator produce the same output without mod- ification.
(3.b) If the latent vector z contains the target feature (z_e), fine-tune the generator to produce a transformed output without the target feature.
Repeat step 3 until the generator does not produce the target feature.
3.4 Target identification in latent space
To determine whether a randomly generated image contains a target feature, we project its latent vector onto the target vector
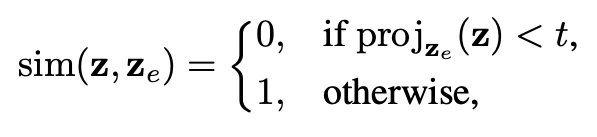
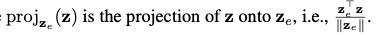
3.5. Unlearning process
let g_θ be the model to be unlearned, f be the pre-trained generator
(3.a) When the randomly sampled latent vector z does not contain the target feature. i.e., sim(z, z_e) = 0

generated outputs from g_θ and f should be same
(3.b) When the randomly sampled latent vector z contains the target feature

Create target-erased output with f.

If the projection can correctly measure the presence of the target feature in the latent space while disentangling the other features, g_θ can successfully forget the target feauture in the latent space.
Add perceptual loss
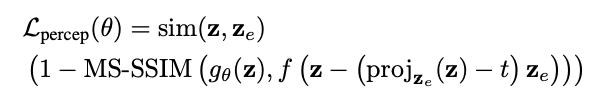
l1, l2 loss occurs in blurry effects in image generation and restoration task.
To overcome the blurry effects, add perceptual loss.
MS-SSIM function refers to the Multi-Scale Structural Similarity, which measures perceptual similarity between two images by comparing luminance, contrast, and structural information.
Final Loss

alpha is a hyper parameter regulates the unlearning/reconstruction error balance.
4. Experiments
1) how well the unlearning is done
2) how good the sample qualities are.

Unlearned model shows similar target-feature ratio to oracle.
*used pre-trained MobileNet to classify the existence of target feature

Check how many features were changed after unlearning by human.

1-2 changed ratio is quite high
- person with ‘Glasses’ are more likely to be elderly.
- the identified target feature vector is likely to be entangled with the ‘Young’ feature.
5. Adversarial Attack
The purpose of this attack is to determine whether the unlearned model can be manipulated to produce images that contain the target feature, even after it has been supposedly removed.

h(x) : pre-trained feature classifier capable of classifying the target feature.
PGD attack finds the latent variable generating a sample that can be classified as the one with the target feature.

un-learned model generates less number of target images than the original model while maintaining high image quality in terms of IS and FID



