
Momentum
- 새 batch에 대한 weight를 조정할 때, 이전 배치에서 계산한 gradient의 관성을 유지한다.
- 현재 위치에서의 gradient와 현재까지의 momentum을 가지고 구한다.
- batch에 따라 gradient가 요동치는 상황에서 효과가 있을 수 있다.

- local minimum convergence를 방해해서 local minimum를 벗어나는데 활용될 수 있다.
Nesterov Accelerated Gradient
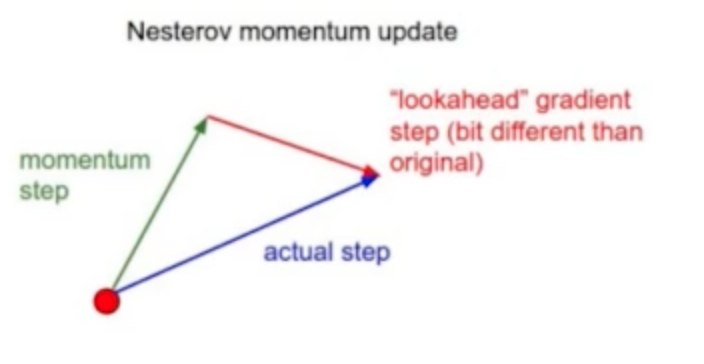
- 현재까지의 momentum과 해당 momentum이 안내하는 곳으로 이동한 곳에서의 gradient를 가지고 구한다.
- converging 속도가 빠르다.

Adagrad
- 많이,자주 변한 파라미터 w1에 대해서는 앞으로 적게 변화시키고, 적게,조금 변한 파라미터 w2에 대해서는 많이 변하게 한다.
- 파라미터가 얼만큼 변했는지를 저장해두고 이를 제곱해서 더하여 Gt를 도출한다.
- Gt를 역수로 집어 넣어줌으로써 많이 변한애는 조금, 조금 변한 애는 많이 바꿔준다.
- 이를 adaptive learning이라고 한다.
- Gt는 이전 timestep 부터의 기울기가 누적되는 합이다. 따라서 G가 계속해서 커지면 시간이 갈수록 학습이 더뎌지거나 멈출 수 있다는 문제가 있다.
Adadelta
- adagrad가 갖고 있던 G가 계속 커지는 문제를 해결한다. G가 계속 커지는 걸 제한한다.
- 감마를 곱해서 Gt-1은 적게 반영하고 새로운 gradient는 조금 더 크게 반영한다.
- Adagrad에서 G는 sum이였지만 여기서는 지수이동평균으로 Gt가 커지는 것을 제한할 수 있다.
- learning rate이 없다.
- 잘 사용되지는 않는다. 그만 알아보자.

RMSprop
- 마찬가지로 지수이동평균으로 Gt를 구해서 adaptive learning을 적용한다.
Adam
- gradient 크기의 변화를 고려하면서도(adaptive learning) 이전 gradient에 해당하는 momentum도 같이 활용한다.
'boostcamp AI tech > boostcamp AI' 카테고리의 다른 글
| AlexNet, VGGNet, GoogleLeNet, ResNet, DenseNet (2) | 2023.11.22 |
|---|---|
| Regularization (1) | 2023.11.21 |
| Multi gpu training, Hyper parameter Search, etc (0) | 2023.11.16 |
| Monitoring tools (0) | 2023.11.15 |
| Model save, load & Transfer Learning (0) | 2023.11.15 |



