Back Propagation Through Time (BPTT)
States computed in the forward pass must be stored until they are reused during the backward pass, so the memory cost is also O(τ).

Loss function
Let's say we are using cross-entropy loss
Derivative of loss with respect to Wyh
derivative of cross entrophy loss w.r.t. ot is (yt^ - yt)
derivative of cross entrophy Loss w.r.t. softmax and derivative of output(t) w.r.t. Wyh
Derivative of loss with respect to Bias by
Derivative of loss with respect to hidden state
at the time-step t+1, we can compute the gradient and further use backpropagation through time from t+1 to 1 to compute the overall gradient with respect to Whh
Aggregate the gradients with respect to Whh over the whole time-steps with backpropagation,
Derivative of loss with respect to Wxh
at the time-step t+1
we can take the derivative with respect to Wxh over the whole sequence as
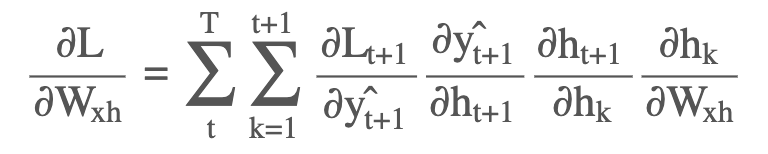
vanishing gradient and exploding gradient
large increase in the norm of the gradient -> explode
opposite -> vanish, making it impossible for the model to learn correlation between temporally distant events.
그래서 backpropagate되는 gradient들을 적당히 끊어주는 truncated rnn을 사용할 수있다.
이런 이유로 LSTM, GRU가 대체로 많이 사용된다.
'boostcamp AI tech > boostcamp AI' 카테고리의 다른 글
| Maximum Likelihood Estimation (0) | 2023.11.12 |
|---|---|
| Bayes Theorem (0) | 2023.11.10 |
| Recurrent Neural Networks (0) | 2023.08.23 |
| Convolutional Neural Network (0) | 2023.08.23 |
| Autoencoder (0) | 2023.08.17 |



