

- 우리는 그동안 activation function으로 sigmoid 함수를 사용했었다. sgmoid 보다 더 나은 선택지들을 알아보자.
- tanh function이 sigmoid보다는 더 좋은 성능을 보이지만 마지막 output layer에 대해서는 sigmoid를 사용한다. 왜냐하면 binary classification의 결과는 0 또는 1 이어야 하기 때문이다.
- tan는 z가 커지거나 작아질때 기울기가 0에 가까워진다는 단점이 있다.
- 그래서 다른 선택지로 ReLU가 있다. 가장 많이 쓰이는 activation function이다.

- 그렇다면 왜 neural network는 non-linear activation function을 사용해야 할까?
- 실제로 sigmoid(z)를 그냥 z라고 하고 output을 계산해보자.
- 결과를 살펴보면 아무리 여러 layer를 지나더라도 linear한 결과 이상을 표시할 수 없게 된다.
- backward propagation을 위해서는 activation function의 slope를 구해야 한다.
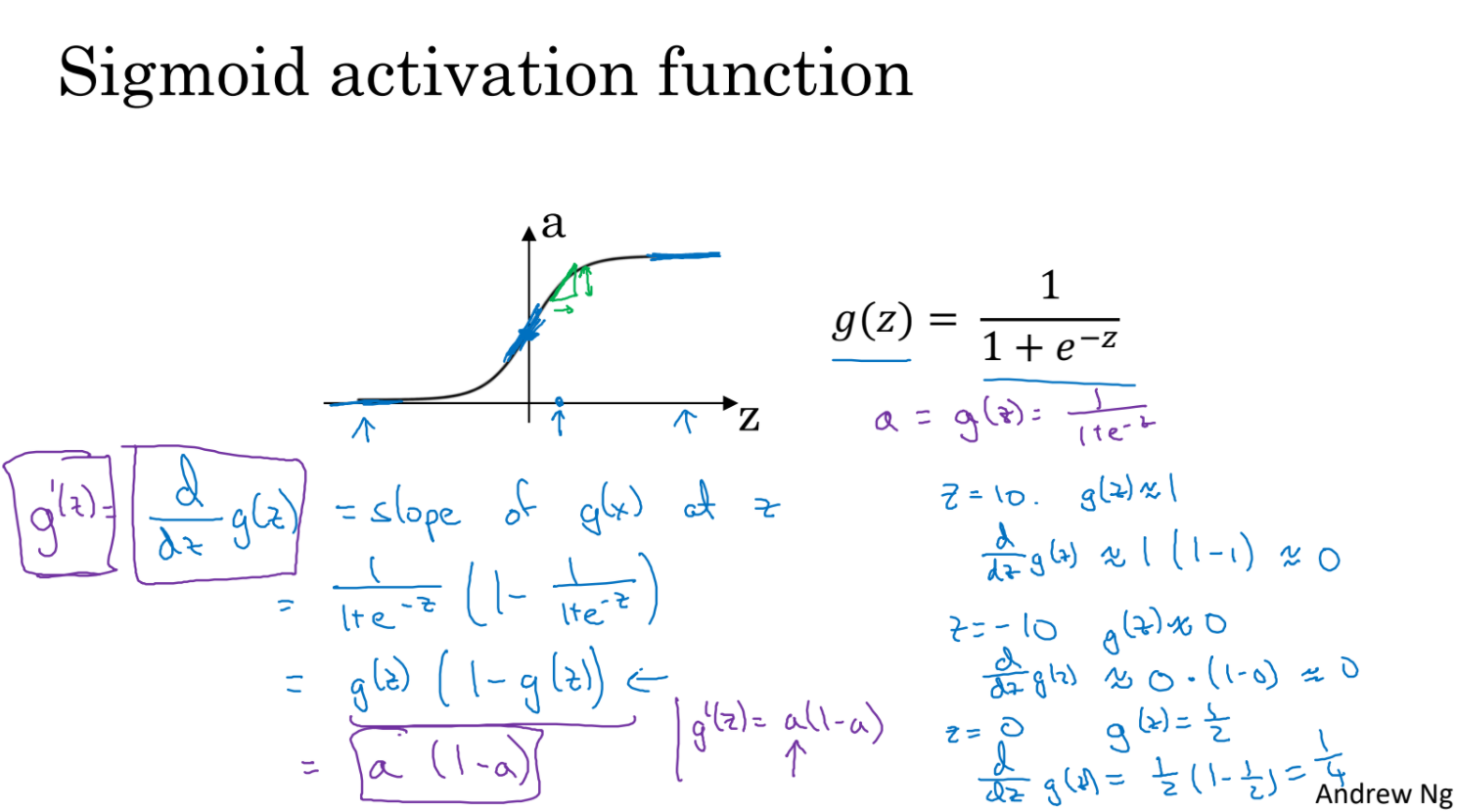
- sigmoid function의 derivative를 구한다.
- z가 충분히 커지거나 작아지면 기울기는 0에 가까워진다.

- tahn function의 derivative를 구한다.
- z가 충분히 커지거나 작아지면 기울기는 0에 가까워진다.

- ReLU function의 derivative를 구한다.


- parameter가 w[1], b[1], w[2], b[2]로 주어졌을 때 forward, backward propogation을 살펴보자.

- 2 layer neural network예시에서 gradient를 구하는 과정은 da -> dz -> dw,db를 구하는 과정이다.
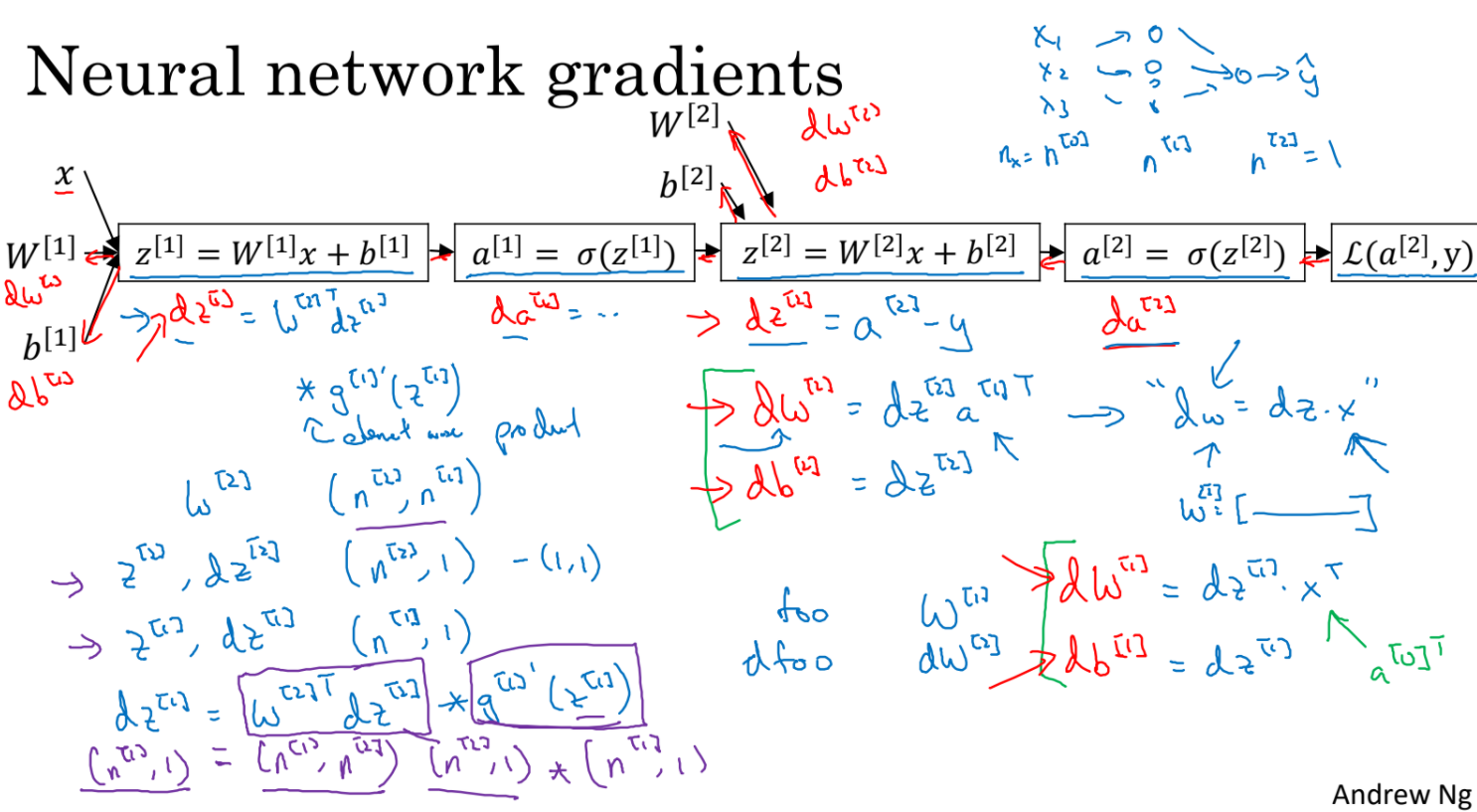
- 3 layer neural network예시에서 gradient를 구하는 과정이다.

- 그럼 이제 back propagtaion 과정을 vectorize해보자.

- 맨 처음 weight를 0으로 initialize하면 어떻게 되는가?
- 만약 weight가 전부 0으로 시작한다면 a1[1], a2[1]의 결과가 같아지고 결국 dz1[1], dz2[1]도 같아지고 결국 같은 동작을 반복하게 된다.
- w[1]은 결국 같은 row만 반복될 것이다. 모든 hidden unit이 같은 동작만 수행하게 된다.

- 따라서 w[1]을 random하게 초기화하고 0.01같은 아주 작은 값의 곱으로 initialize한다.
- 그럼 hidden unit들이 서로 다른 계산을 하게 된다.
- 왜 0.01같이 아주 작은 값을 사용하는가? sigmoid 함수를 살펴보자. 100같이 큰 값을 곱해버리면 너무 z가 너무 빠르게 커지고 빠르게 기울기가 0으로 수렴하게 된다. 즉 gradient가 점점 작아져서 training이 매우 느려질 수 있다.
'ComputerScience > Machine Learning' 카테고리의 다른 글
| Deep Learning 1-4-2 (0) | 2021.09.14 |
|---|---|
| Deep Learning 1-4-1 (0) | 2021.09.14 |
| Deep Learning 1-3-1 (0) | 2021.09.10 |
| AI - 2. Search (0) | 2021.09.09 |
| Deep Learning 1-2-2 (0) | 2021.09.07 |



