Transformer
The Illustrated Transformer Discussions: Hacker News (65 points, 4 comments), Reddit r/MachineLearning (29 points, 3 comments) Translations: Arabic, Chinese (Simplified) 1, Chinese (Simplified) 2, French 1, French 2, Italian, Japanese, Korean, Persian, Rus
jsdysw.tistory.com
지난번에 이어서 한번 더 공부내용을 다시 정리해보려한다.
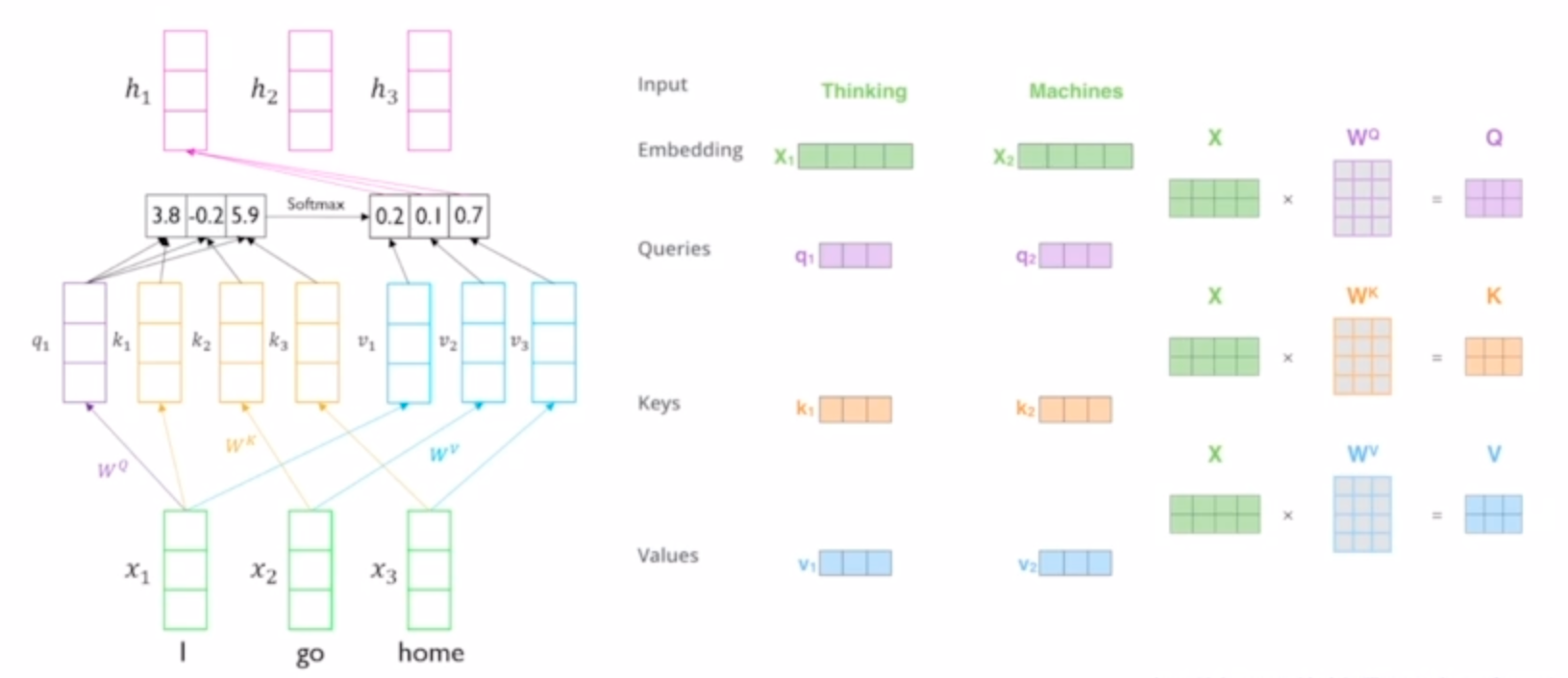
input 단어의 embedding vector는 Wq, Wk, Wv 변환을 각각 거처서 query, key, value 벡터로 변환된다.
q1은 k1, k2, k3와 각 softmax(유사도)를 구한다. 이 score가 각 v1,v2,v3에 가중치로 적용된다. 가중치가 적용된 v1,v2,v3의 합을 구하면 최종 encoding vector h1이 만들어진다.
이 h1은 input 단어들 중에 가장 relevant한 녀석들을 강하게 고려한 결과물이 된다. 어떤 길이의 timstep이어도 영향을 받을 수 있다.
모든 input단어들 에 대해 self-attention을 적용하면 총 세개의 h1, h2, h3 인코딩 벡터들이 만들어진다. 행렬연산의 관점으로 바라보면 설명한 것보다 더 간단하다.
Query와 key의 차원은 같아야하지만 v의 차원은 이 둘과 무관해도 된다.
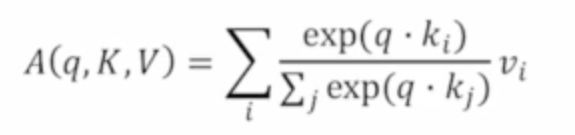
수식을 살펴보자 query vector 한개, (K,V)쌍들의 집합을 인수로 받는 attention A = query를 모든 k에게 날리고 구한 softmax 결과물 weighted sum of values.

이번에는 q하나가 아니라 모든 q들을 나타내는 Q를 받아서 계산하는 행렬식을 살펴보자.
Q, K를 곱한 결과 행렬은 각 query의 attention 유사도들이 row로 쌓여 있는 셈이다. 여기 softmax를 거쳐서 attention distribution으로 변환한다.

이제 value들마다 각 value에 해당하는 weight를 곱하고 더한 값이 결과물의 row로 계산된다.
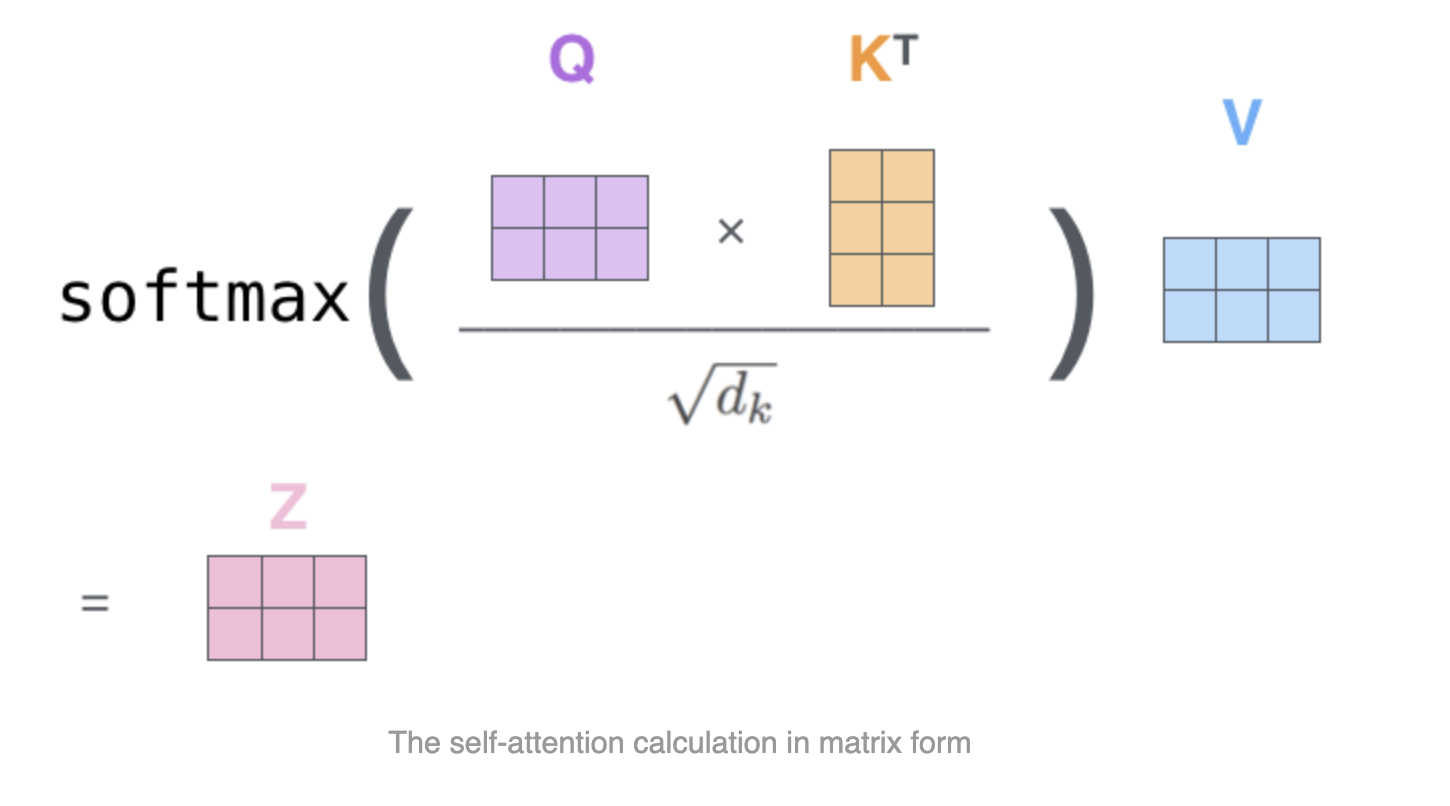
위 그림에 보면 dk 제곱근으로 스케일링이 적용된것이 보인다.
q, k벡터의 길이가 길면 길수록 softmax를 거쳤을때 distribution이 큰 값(하나의 key쪽으로)으로 쏠리는 현상이 생긴다.
이를 안정하기 위해 dk를 나누는 작업을 거친다.
'boostcamp AI tech > boostcamp AI' 카테고리의 다른 글
| Self-Supervised Pre-training Model (GPT-1, BERT) (0) | 2023.12.07 |
|---|---|
| Transformer - Multi-Head attention (2) | 2023.12.06 |
| BLEU, Precision-Recall (0) | 2023.11.30 |
| Beam search (1) | 2023.11.30 |
| Seq2Seq with attention (1) | 2023.11.30 |



