*자세한 내용은 https://jsdysw.tistory.com/470
[Paper Review] NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
Neural Machine Translation by Jointly Learning to Align and Translate Neural machine translation is a recently proposed approach to machine translation. Unlike the traditional statistical machine translation, the neural machine translation aims at building
jsdysw.tistory.com
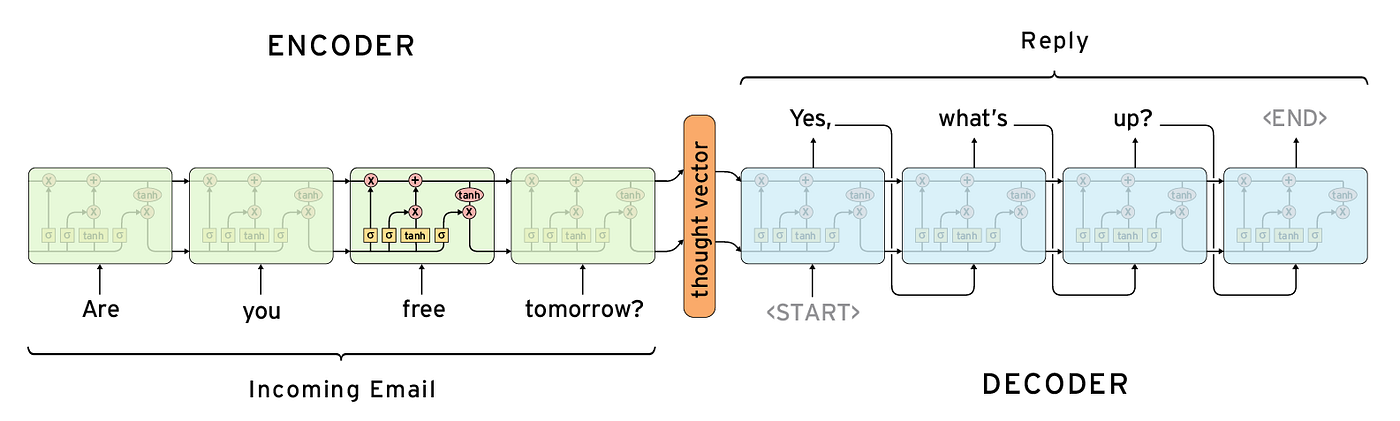
고정된 크기의 hidden state vector를 사용한다는 점에서 문장이 길어질 때 초반 정보를 많이 잃어버리는 경향이 있었다.
-> trick으로 입력문장을 reverse해서 집어넣었다. 적어도 시작 단어들은 decoder와 가깝게 배치해서 초반 문장을 잘 생성하게 했다.
-> attention이 등장하면서 hidden state vector가 사라졌다.
-> decoder 생성 시점에 나와 가장 relevent한 입력 토큰의 영향을 크게 받도록 한다.
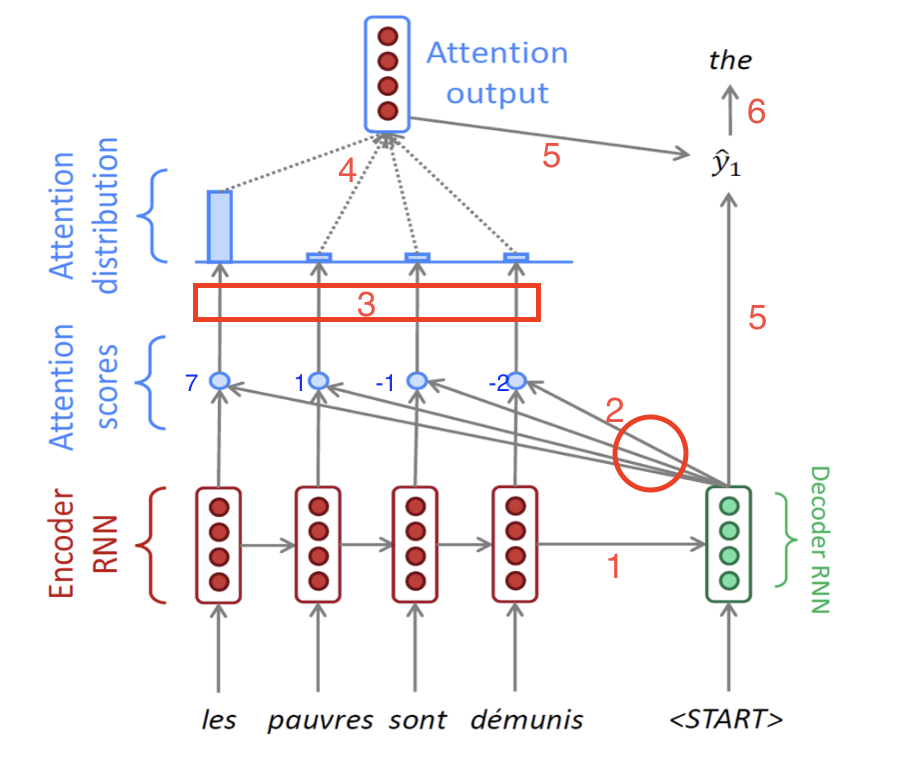
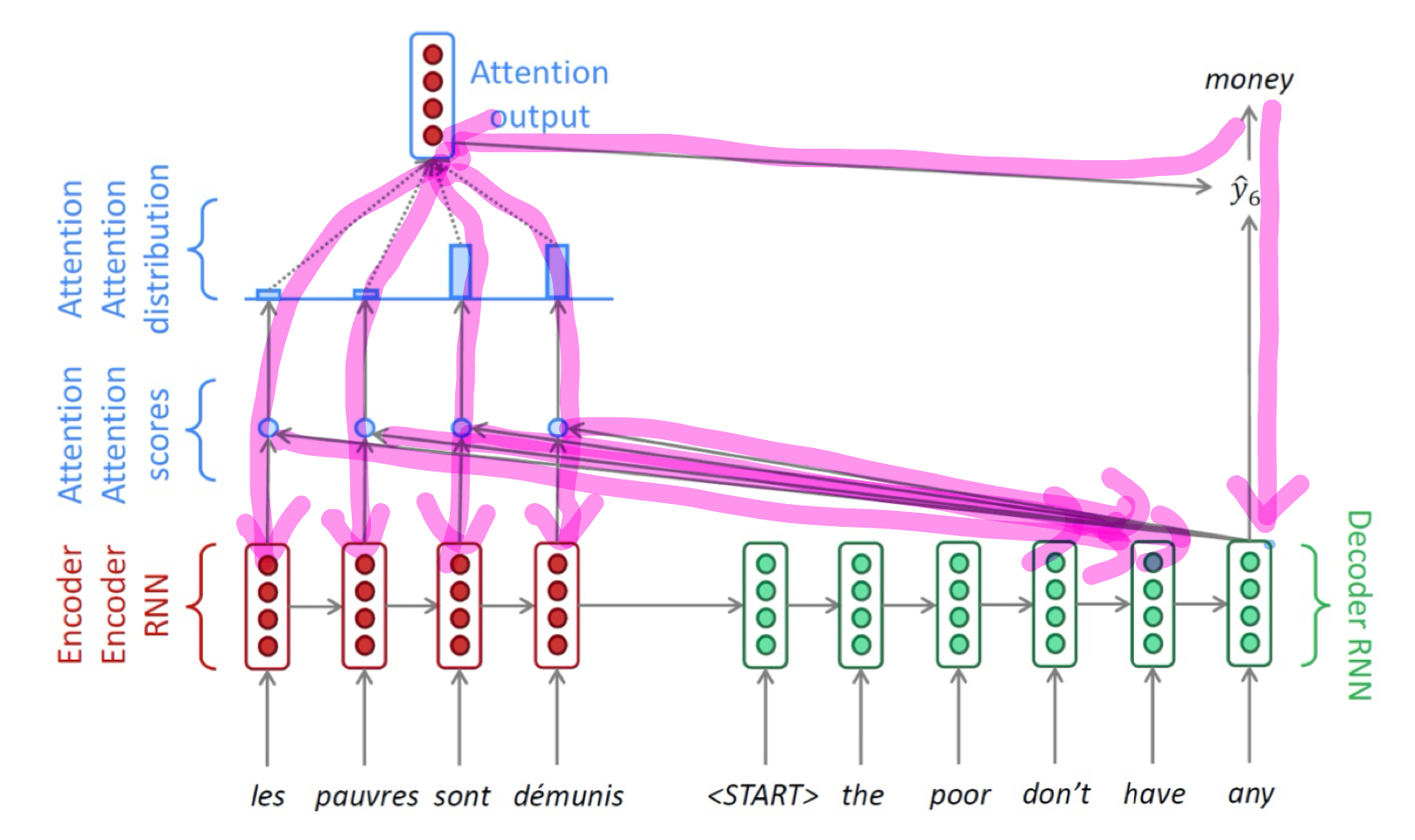
1. input sequence가 encoder를 돌면서 encoder hidden state h(e)1, h(e)2, h(e)3, h(e)4를 생성한다.
1-1. 제일 마지막 h(e)4와 <SOS>를 받아서 decoder는 h(d)1을 만든다.
1-2 이전 h(d)t-1과 input token을 받아서 decoder는 h(d)t를 만든다.
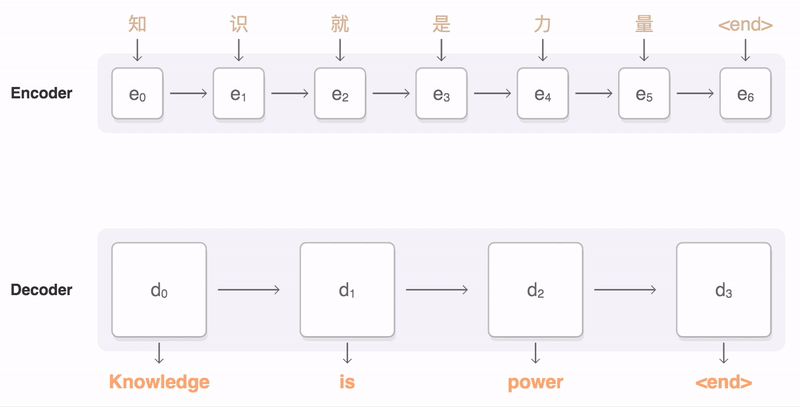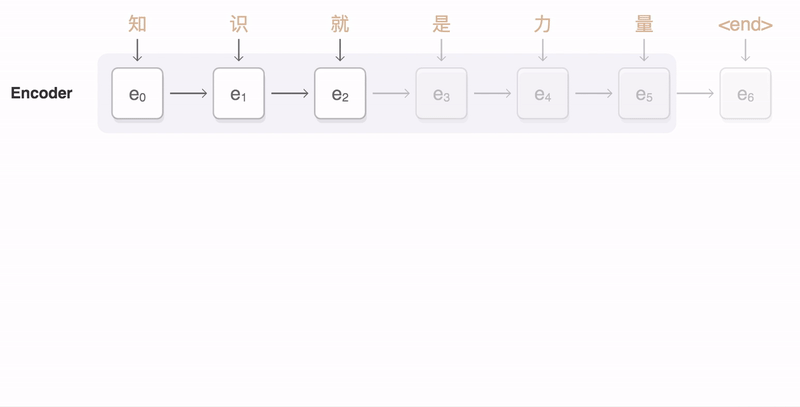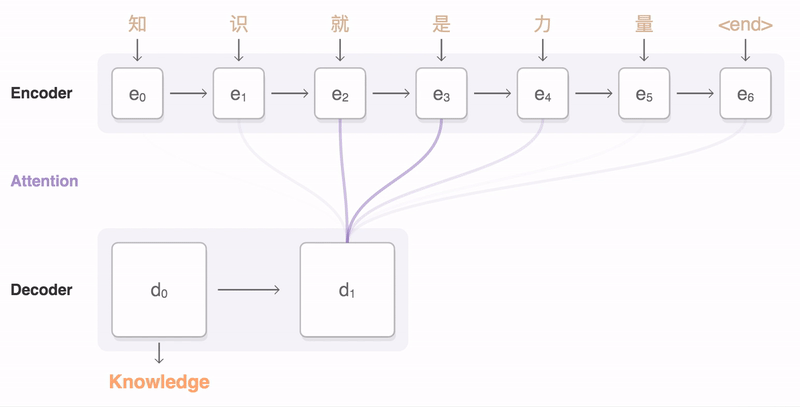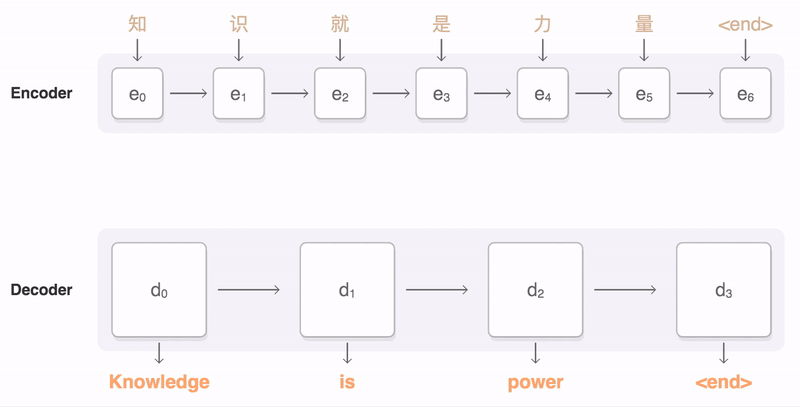
2. t시점 decoder의 hidden state h(d)t 를 각 h(e)들과 내적(유사도 계산)하여 attention scores 계산
3. attention scores를 softmax에 거치도록 하여 확률값으로 변환 (attention distribution, attention vector)
4. attention distribution을 weight로 하여 h(e)들에 반영하여 합을 구함 (attention output, sum of multiplications)
5. attention output을 context vector라고 부른다. context vector와 t시점 decoder의 h(d)t 를 함께 사용하여 예측 y_t를 만든다.
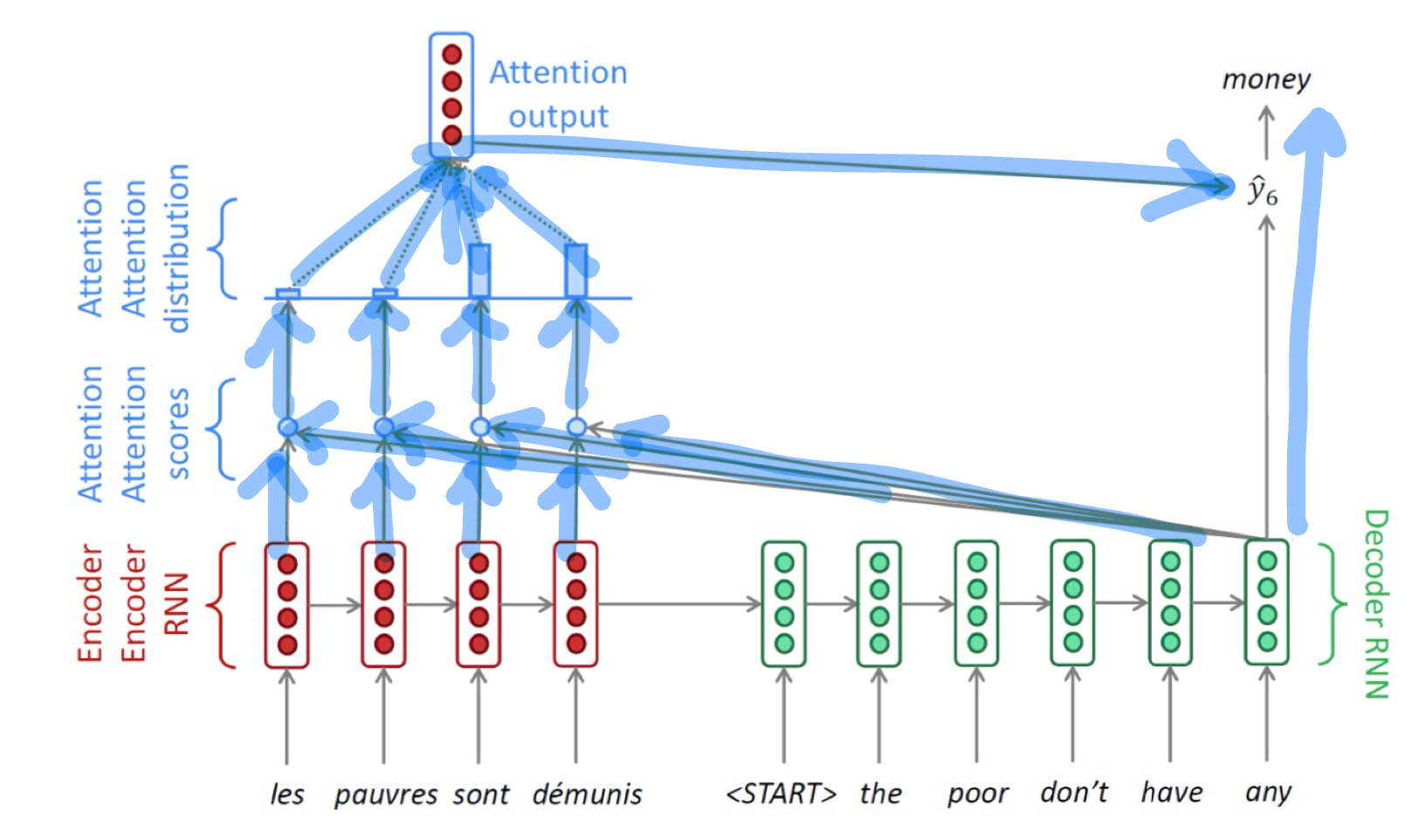
학습 이후에 decoder는 이전 예측 단어를 다음 스텝에 input으로 넣어준다.
학습을 할 때는 이전 예측이 틀릴 수도 있으니 ground truth를 다음 Input에 넣어준다. (teacher forcing)
학습을 할 때 꼭 teacher forcing만을 사용 해야하는 건 아니다.
초기 학습에서는 teacher forcing을 사용하다가 후반부에서는 test 환경과의 괴리를 없애기 위해 이전 Prediction을 현재 input으로 가져와서 쓸 수 있다.
1. Attention Mechanisms
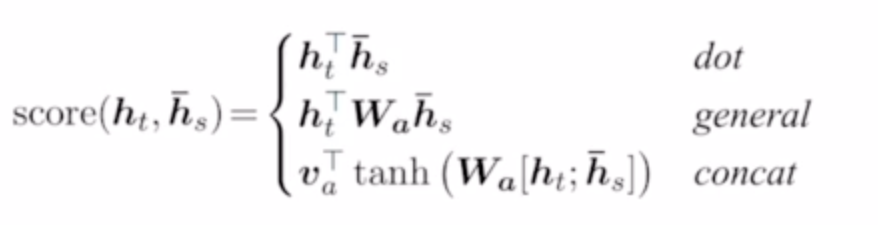
현 시점 decoder의 hidden state벡터 h_t와
encoder의 s시점 hidden state vector를 h_s라고 하자
이 둘의 attention score를 계산하는 방법은 여러가지가 있다.
- dot : 그냥 곱
- general : 학습 가능한 linear transformation matrix Wa를 사이에 둔다.
바다나우 어텐션이라고도 불리는 마지막 방법을 알아보자.
여기서는 가정이 조금 다르다. 현 시점은 t+1이다. decoder의 이전 hidden state h_t와 encoder의 output h_s를 가지고 attention score/value를 계산한다. 추가로 이렇게 생성한 attention value와 t+1 시점 입력 단어를 concat해서 새로운 RNN의 입력단어로 사용한다.
- concat : [h_t, h_s] 두개를 concat하고 첫번째 linear layer(Wa) + activation을 거친 다음 다시 두번째 linear layer(va)를 거쳐서 스칼라 값을 만든다. 2층으로 구성된 neural net이 유사도 계산을 학습하도록 한다.
2. Backpropagation
화살표 선들이 각각 weight, bias를 갖고 있는 부분이다. forward의 역방향으로 backpropagation이 진행된다.
d loss/ d W_decoder
d loss/ d W_output_layer
d loss/ d W_for_attention_score
d loss/ d W_encoder
3. Pros
장점은 논문에서 많이 다뤘다. vanishing grandient 문제만 한번 더 짚고 넘어가자.
attention이 없었다면 loss가 첫 input 단어 위치 까지 전달되는 상황에서, decoder timestep을 다 훓고 encoder timestep을 다 훓어서 W가 계속 곱해지며 전파된다.
attention에서는 이럴 필요가 없다. 위 그림에서 처럼 attention output을 거쳐서 바로 각 timestep으로 gradient가 떨어진다.
게다가 attention distribution을 살펴보면 예측 시점에서 input 정보들 중 누구를 집중해서 보았는지가 관찰 가능하다.
이 모든 과정이 end-to-end 학습이 가능하다.
'boostcamp AI tech > boostcamp AI' 카테고리의 다른 글
| BLEU, Precision-Recall (0) | 2023.11.30 |
|---|---|
| Beam search (1) | 2023.11.30 |
| Long-Short Term Memory, GRU (0) | 2023.11.29 |
| Word Embedding - Word2Vec, GloVe (1) | 2023.11.27 |
| Naive-Bayse Classifier (1) | 2023.11.27 |



