1. Pattern?
- 얼굴, 지문, 글씨 등에 패턴이 존재한다.
- 유사성을 갖는 특징, 속성들의 집합을 말한다.
- 사람의 얼굴들에는 눈, 코, 입 등의 속성들로 이루어진 패턴들이 존재한다. 인종, 남성, 여성에 따른 차이가 존재하지만 동일한 패턴의 범주에 존재한다.
2. 인식
- 패턴들로 부터 특징들을 꺼내고 최종 class로 구분하기 위한 분류작업이 이루어지는 것을 말한다.
- 예를들면 얼굴 사진으로부터 얼굴 크기, 코의 모양, 눈썹의 짙은 정도, 눈의 크기 등의 feature를 꺼내고 그 정도에 따라 알고있는 지식에 기반해서 "누구다"라는 결정을 내리게 된다.
- 일반적인 인식의 프로세스를 살펴보면 다음과 같다.
1. 데이터베이스 수집
2. 특징 설계 : 색상, 크기 등의 주요한 특징들을 feature로 설계하는 것이다.
3. 분류기 설계 : 적합한 모델과 학습 방법을 선택해서 분류기를 학습시킨다.
4. 성능평가
3. Database 수집
- 여러 sample들을 먼저 수집해야 한다.
- (학습도중)학습을 위한 sample들을 training set
- (학습도중)학습이 잘 되었는지 확인하기 위한 sample들을 test set
- (실전)실전으로 정해진 domain에서의 검증을 위한 sample들의 집합이다.

- 학습을 위한 데이터가 아무리 좋아도 개수가 적으면 학습에서 한계가 존재한다. (quantity)
- 당연히 학습을 위한 데이터는 실세계의 다양성을 반영할 수 있어야한다 (quality)
4. Feature
- 숫자 인식의 예를 살펴보자.

- 이미지의 모든 pixel을 feature로 사용할 수 있고
- 이미지를 세로로 반으로 잘랐을 때 좌우 1의 개수, 가로로 반으로 잘랐을 때 상하 1의 개수를 feature로 잡을 수도 있다. 이 방법으로 feature map에 특징에 따른 분별 결과를 표시해보면 6과 7은 분별력을 갖는 것 같으나 2, 8, 10등은 뭉개져서 사실상 분별력이 없다고 볼 수 있다.
- 즉 feature를 무엇으로 잡느냐에 따라 차원을 늘리지 않으면서 분별력을 갖도록 할 수 있고 이는 항상 어려운 문제이다.
5. Classification
- 특징을 잘 잡았다면 이제 어떤 모델로 분류를 진행할지를 정하게 된다.
- 너무 잘 학습하는 것도 사실 마냥 좋은 것은 아니다. 학습 시간이 적게 걸리는 등의 효율성이 떨어질 수도 있고 너무 과하게 학습데이터를 분류했을 때 실세계의 다양한 변수들에 대응이 오히려 떨어질 수도 있다.
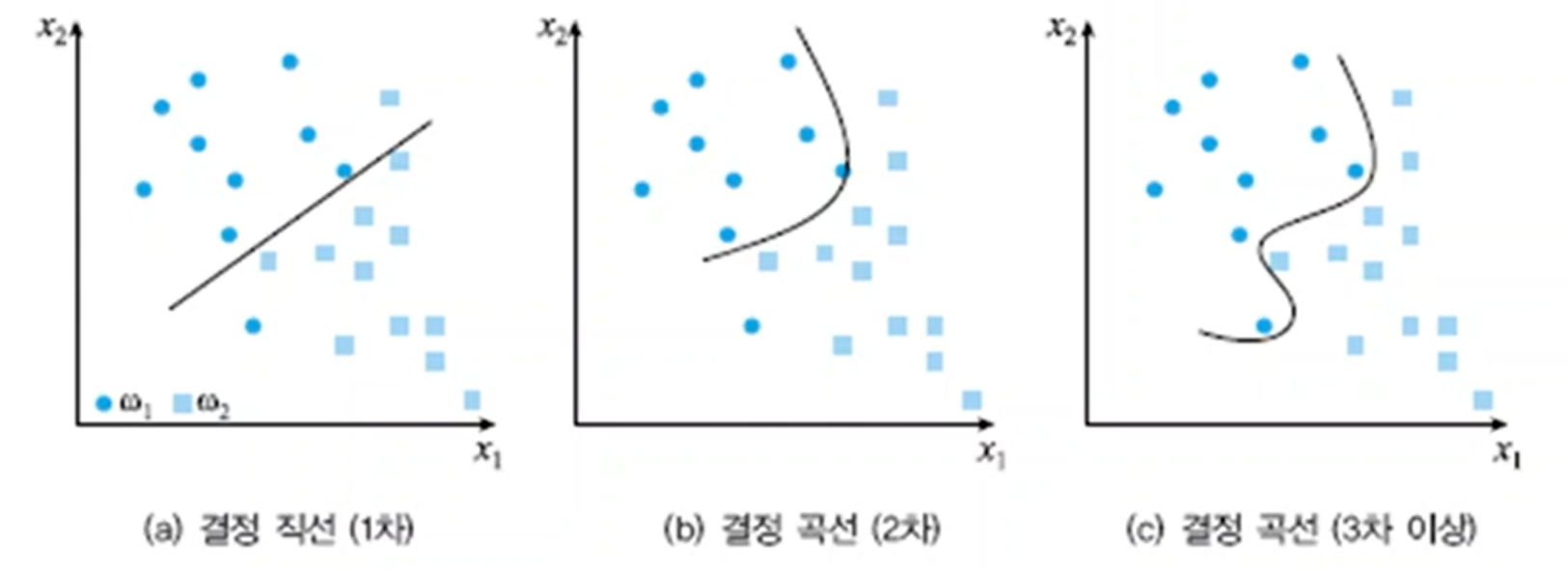
6. Evaluation
- 학습한 결과를 객관적으로 판단하는 단계이다.

- 기각한 샘플 수 라는건 feature가 decision line에 너무 가까운 경우 사용이 부적절하다 판단한 샘플을 말한다.


- confusion matrix는 w1을 w1으로 한 것은 참, w2를 w2로 한 것은 거짓으로 하는 것이다.
- true positive : 사람을 사람이라고 판단
- true negative : 사람을 사람이 아니라고 판단
- false negative : 사람이 아닌 것을 사람이 아니라고 판다.
- false positive : 사람이 아닌 것을 사람이라고 판단
- 정의하는 도메인에 따라 사람을 사람으로 판단하지 않은 상황이 더 중요할 수도 있고 사람이 아닌것은 사람이라고 판단하는 상황이 더 중요할 수도 있다.

- 잠자는 자세에 따른 적합한 침대를 찾는다고 할때 overfitting의 상황을 위의 그림처럼 풍자할 수 있다.
7. Machine Learning
- 컴퓨터가 학습을 할 수 있다면 일일히 모든 상황을 if else등으로 알려주지 않아도 컴퓨터가 많은 일을 할 수 있지 않을까?

- 머신러닝은 인공지능의 한 분야이고 요즘들어 각광받는 딥러닝은 기계학습의 하나이다.
- 영상처리, 자율주행, 광고 추천등에 쓰이고 있다.
- 기계학습도 다양한 분류가 존재한다.

8. Notation
- 기계학습은 항상 입력을 받아서 출력하는 함수 y-f(x)를 학습한다고 생각할 수 있다. (함수 근사)

- Feature는 모델에게 공급하는 입력이다. 가장 간단한 경우에는 입력 자체가 특징이 된다. 예를들면 스팸메일 분류기에서 feature를 이벤트 당첨, 검찰 이라고 설계할 수 있다.
- Sample : 데이터 하나하나를 sample이라고 할 수 있다
- Label : 레이블이 있냐/없냐에 따라 지도/비지도 학습이 될 수 있다.
- Learning : 모델을 만들거나 우리가 원하는 방향으로 배우는 것을 말한다.
- Prediction : 모델이 만들어지면 임의의 x에 대해 y를 내는 것을 말한다.
9. Supervised Learning : Regression
- 입력과 출력이 모두 실수인 데이터를 사용한다.
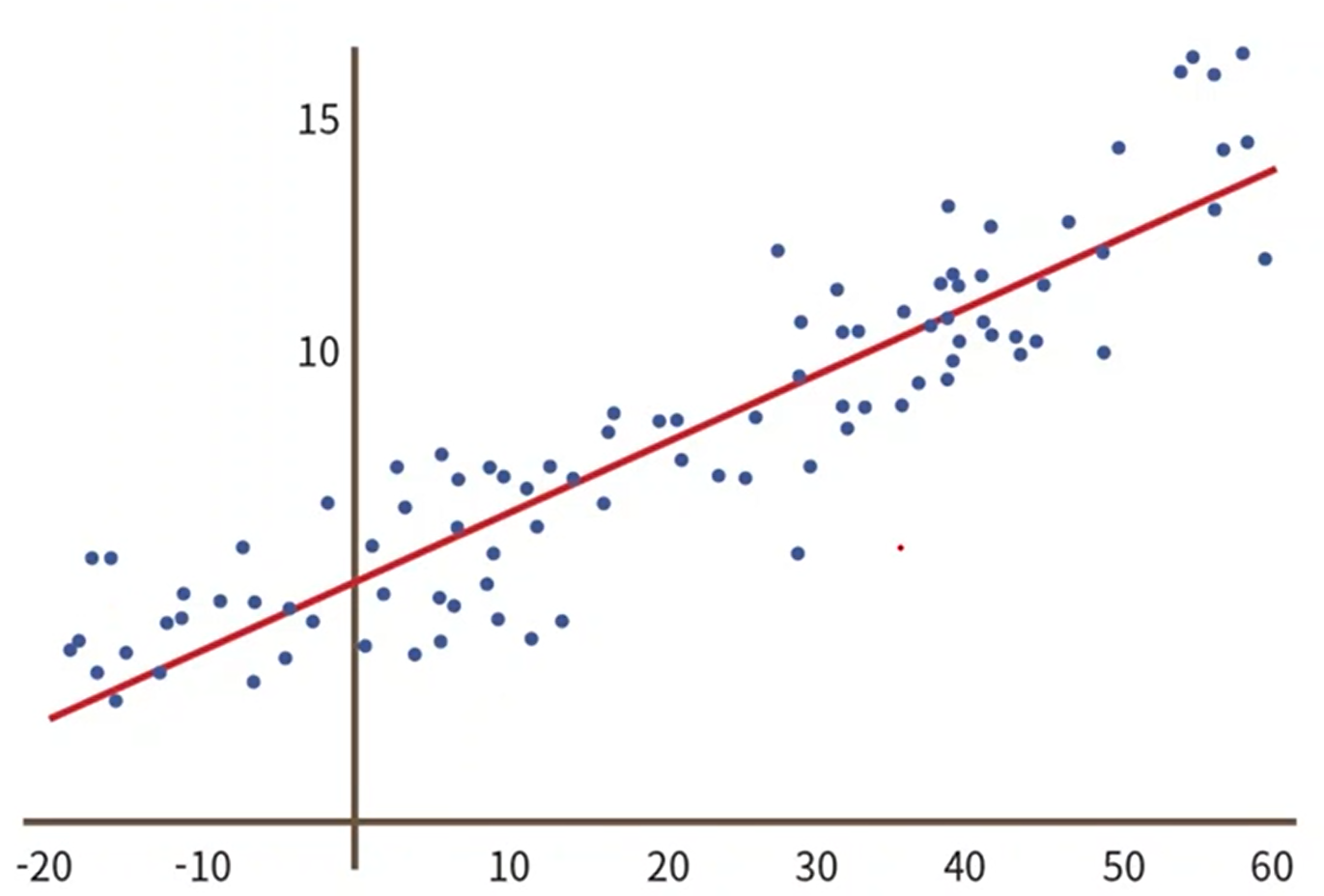
- 실수 입출력에 따른 입력에서 출력으로의 y=f(x)라는 함수를 찾는 것을 회귀라고 한다.
10. Supervised Learning : Classification
- 입력을 두 개 이상의 레이블(유형)으로 분류하는 것
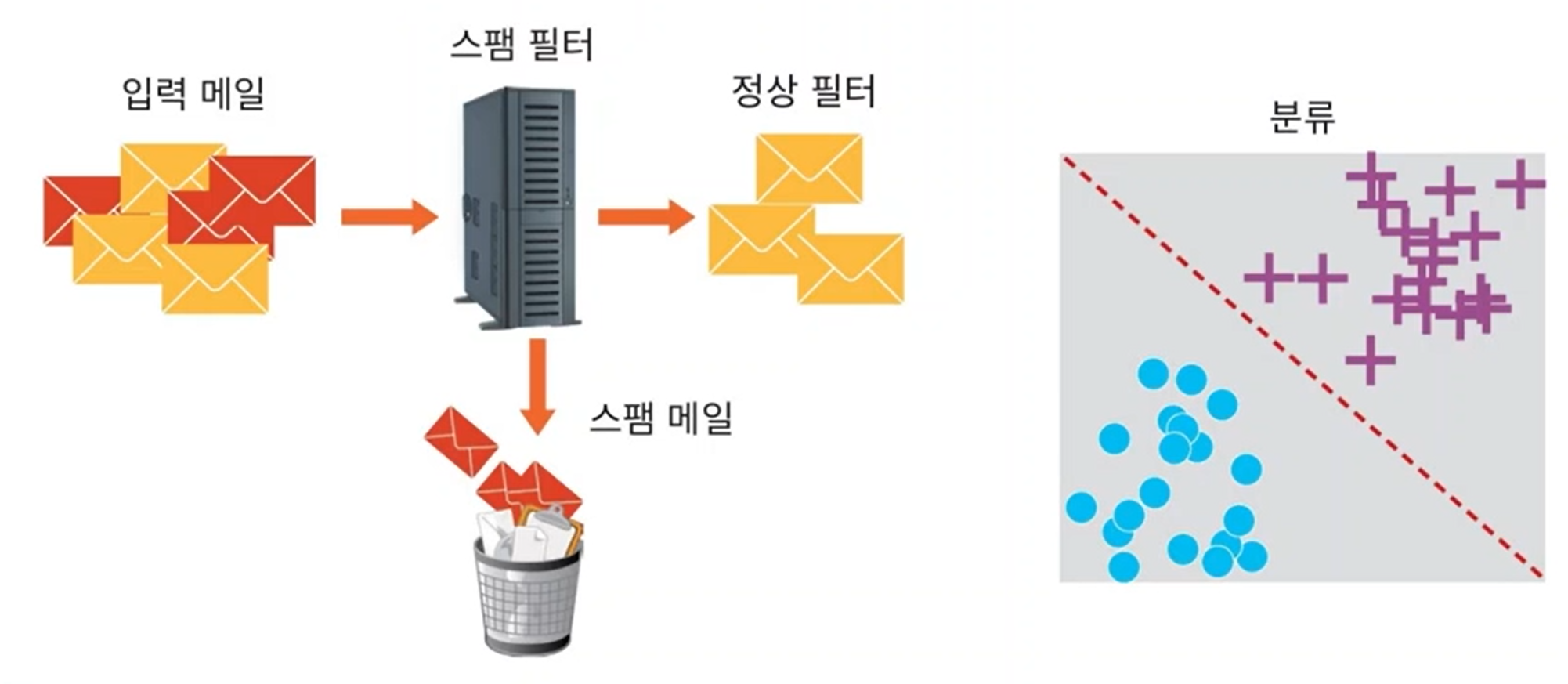
11. Unsupervised Learning
- label을 주어지지 않고 학습하는 것을 말한다.

- ground truth label을 만드는 것은 매우 번거롭고 때로는 어렵다. 또한 실세계의 데이터는 매우 많다.
- 그럼 그냥 충분히 많은 데이터 자체로 학습을 시켜보자! 하는 것이다.

- 데이터를 주었을 때 어느 지점을 중심으로 군집들을 찾는 clustering의 예시이다.
- K가 군집의 중심의 수를 나타낸다.
11. Reinforcement Learning
- 게임에 많이 활용된다. ex)알파고
- 컴퓨터는 보상이 좋은 선택을 하도록 설정되어있고 컴퓨터가 하는 선택에 따른 피드백을 주어 학습하는 것이다.

12. Worth of ml
- 프로그래밍 시간을 줄일 수 있다.
- 많은 예제만 있다면 학습시켜 빠른 시간안에 신뢰성있는 프로그램을 완성할 수 있다.
- 예를들어 번역기를 만든다고 하면 영어, 일본어, 한국어 별로 프로그램을 다시 만들어야 하지만 예제 데이터만 준비하면 쉽게 맞춤형 제품을 생산할 수 있다.
- 프로그래머가 모든 상황에 적합한 알고리즘을 알고 있지 못할 수 있다. 하지만 기계학습은 시도할 알고리즘이 떠오르지 않더라도 데이터만 잘 준비하면 문제를 해결할 가능성이 있다.
'ComputerScience > Machine Learning' 카테고리의 다른 글
| AI - 9. kNN, Gaussian Mixture (0) | 2021.11.11 |
|---|---|
| AI - 8. Linear Regression (0) | 2021.11.08 |
| AI - 6. Uncertainty (0) | 2021.10.12 |
| DeepLearning 2-2-1 (0) | 2021.10.06 |
| DeepLearning 2-1-2 (0) | 2021.10.05 |



