처음부터 목적에 알맞은 layer 수, hidden units의 수 learning rate등의 hyperparameter 값들을 설정할 수는 없다.
여러번의 실험과 검증을 반복하면서 최고의 성능을 낼 수 있는 조건들을 찾아 설계가 진행된다.

데이터를 train/dev/test set으로 분리해서 각 목적에 맞게 사용한다. 데이터를 나누는 비율을 data가 충분히 크다면 98/1/1 의 비율도 적절하다.
train set으로 학습을 하고나면 test set으로 bias가 없는지 variance는 어떤지 검증을 하게 된다.

순서대로 underfitting, 적당한 fitting, overfitting이 된다.
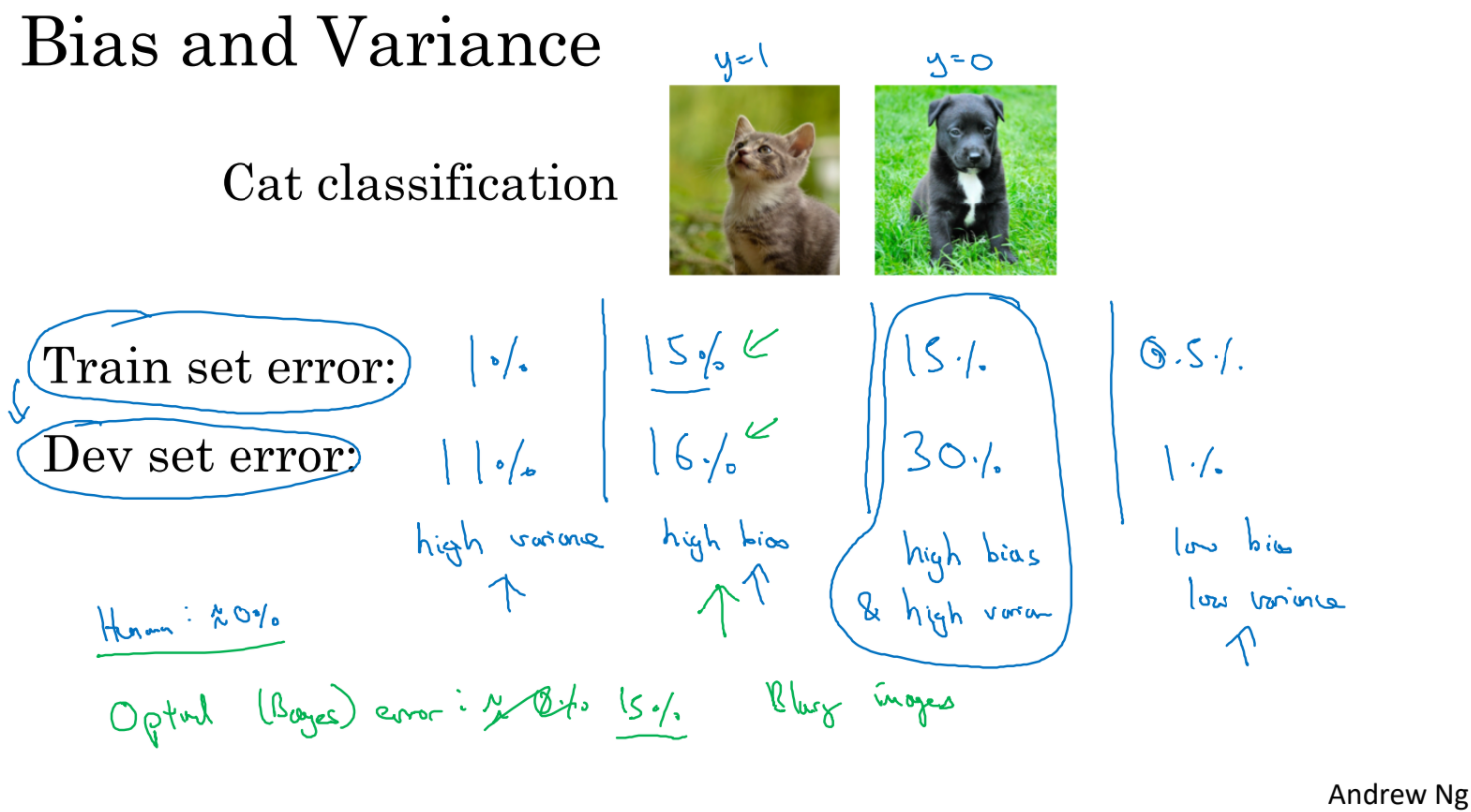
train set error 가 1% dev set error가 11% 라면 overfitting의 가능성이 높다. 이를 high variance라고 한다.
train set error 가 15% dev set error가 16% 라면 underfitting의 가능성이 높다. 이를 high bias라고 한다.
train set error 가 15% dev set error가 30% 라면 high bias & high variance라고 할 수 있다.
train set error 가 0.5% dev set error가 1% 라면 low bias & low variance라고 할 수 있다.
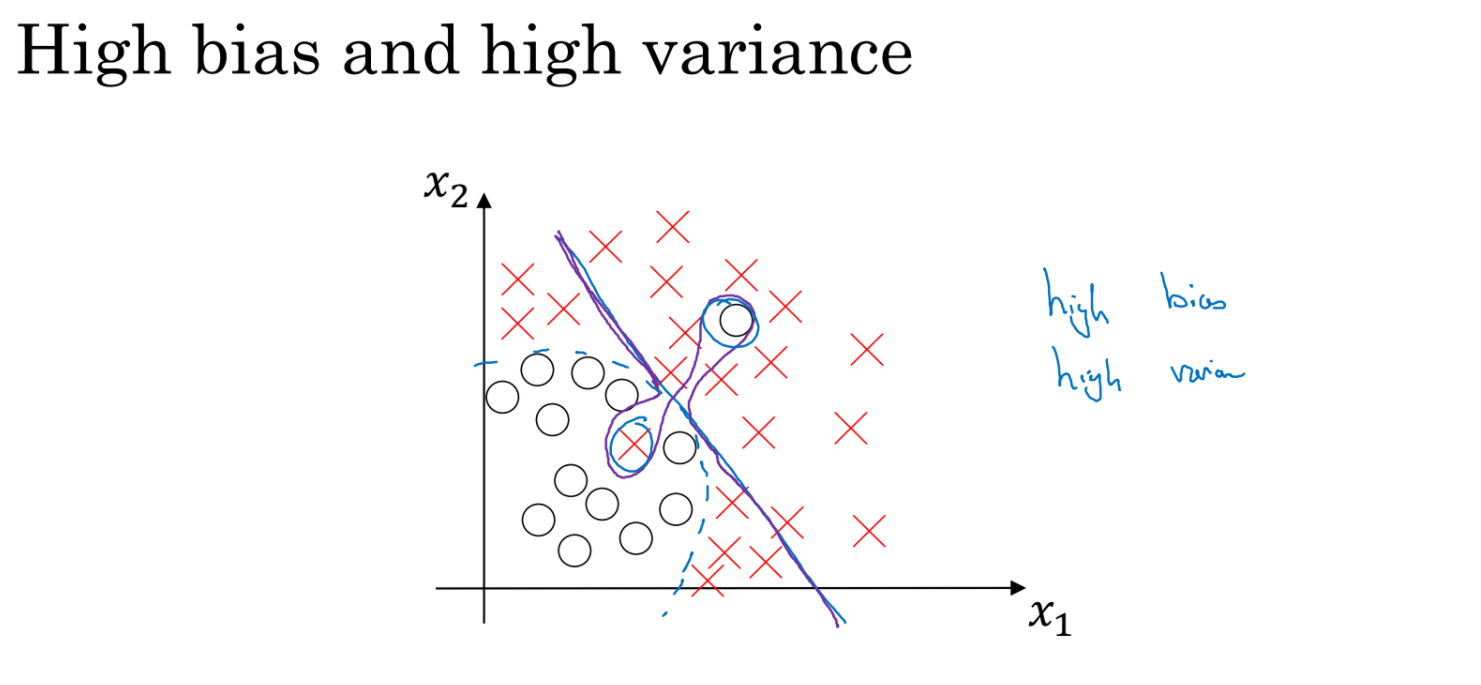
bias와 variance에 따른 가능한 조치들을 살펴보자.

만약 bias가 너무 높다면 network크기를 키우거나 학습을 더 오래 하는 것도 방법일 것이다. 반면 bias는 크지 않은데 variance가 너무 높다면 데이터를 더 많이 수집하거나 뒤에서 배울 regularization으로 overfitting을 막을 수 있다.
bias가 높을때 데이터를 늘리거나 regularization은 별 도움이 안된다. 마찬가지로 variance가 높을때 네트워크 크기를 키우거나 학습을 오래하는 것은 도움이 되지 않는다.
만족스러운 결과를 낼 때까지 위의 과정을 반복하는 것도 가장 기본적인 ML 개발 방법이다.

regularization 은 overfitting(variance가 높아지는 것)을 막기위해 사용한다.
L2 regularization과 L1 regularization을 살펴보자. 람다는 regularization 파라미터이다.
보통은 L2를 많이 사용한다.

cost function에 람다/2 * L2 norm을 더해준다. cost function을 미분해서 gradient를 구하는 과정까지 나와 있다. regularization는 weight를 업데이트 하기위한 gradient를 약하게 하기 때문에 weight decay라고도 부른다.
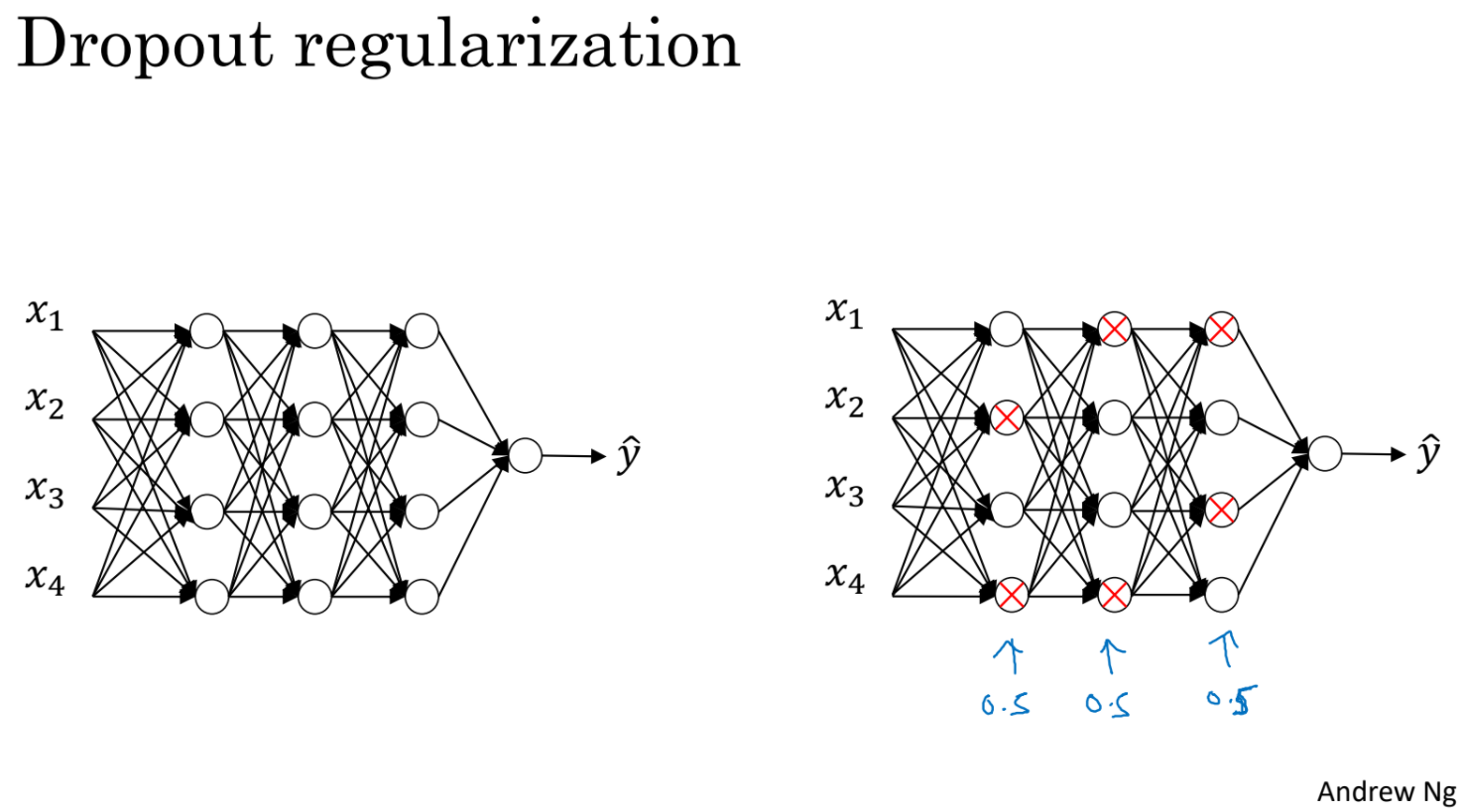
dropout regularization은 학습중 특정 확률로 어떤 unit의 계산을 건너 뛴다. 미친것 같지만 아주 잘 작동하는 방법이고 전체보다 적은 unit들의 network를 거치기 때문에 regularization 효과가 있다.
test set에 대해서는 dropout을 사용하지 않는다.

각 layer의 unit들마다 keep prob으로 unit을 activate/deactive할지 확률이 정해져있다. 어떤 layer가 지나치게 overfitting하고 있다면 낮은 keep prob을 설정할 수 있을 것이다. 1인 경우는 dropout을 사용하지 않는 layer이다.
computer vision에서는 데이터가 부족한 경우가 많아 overfitting을 줄이기 위해 dropout을 많이 사용한다.
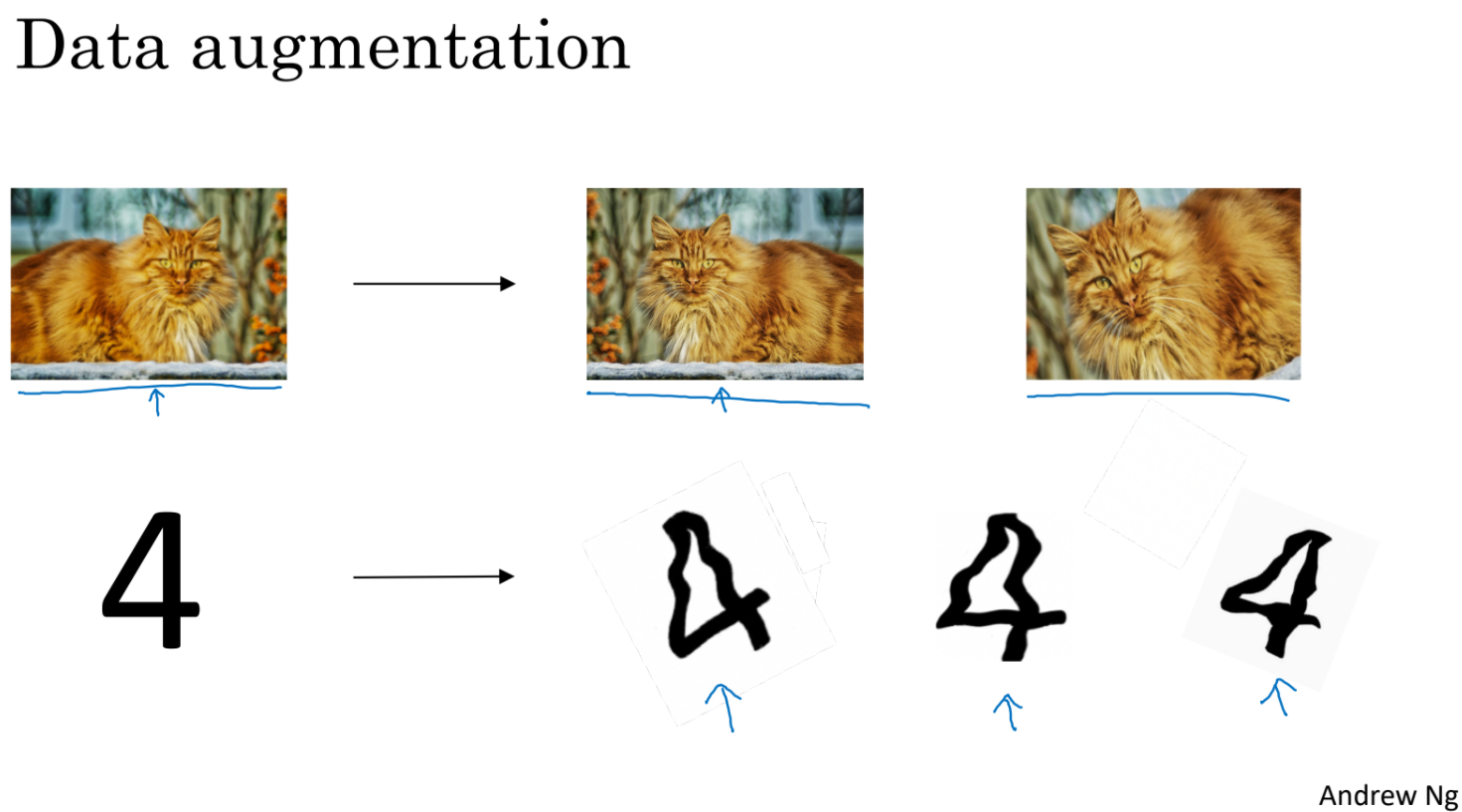
학습할 데이터를 구하는 일은 비용이 많이 든다. 따라서 기존의 데이터를 뒤집거나 회전하는 등으로 data set의 크기를 키울 수 있다. 이렇게 학습데이터를 늘리는 것도 overfitting을 막는 한가지 방법이다.
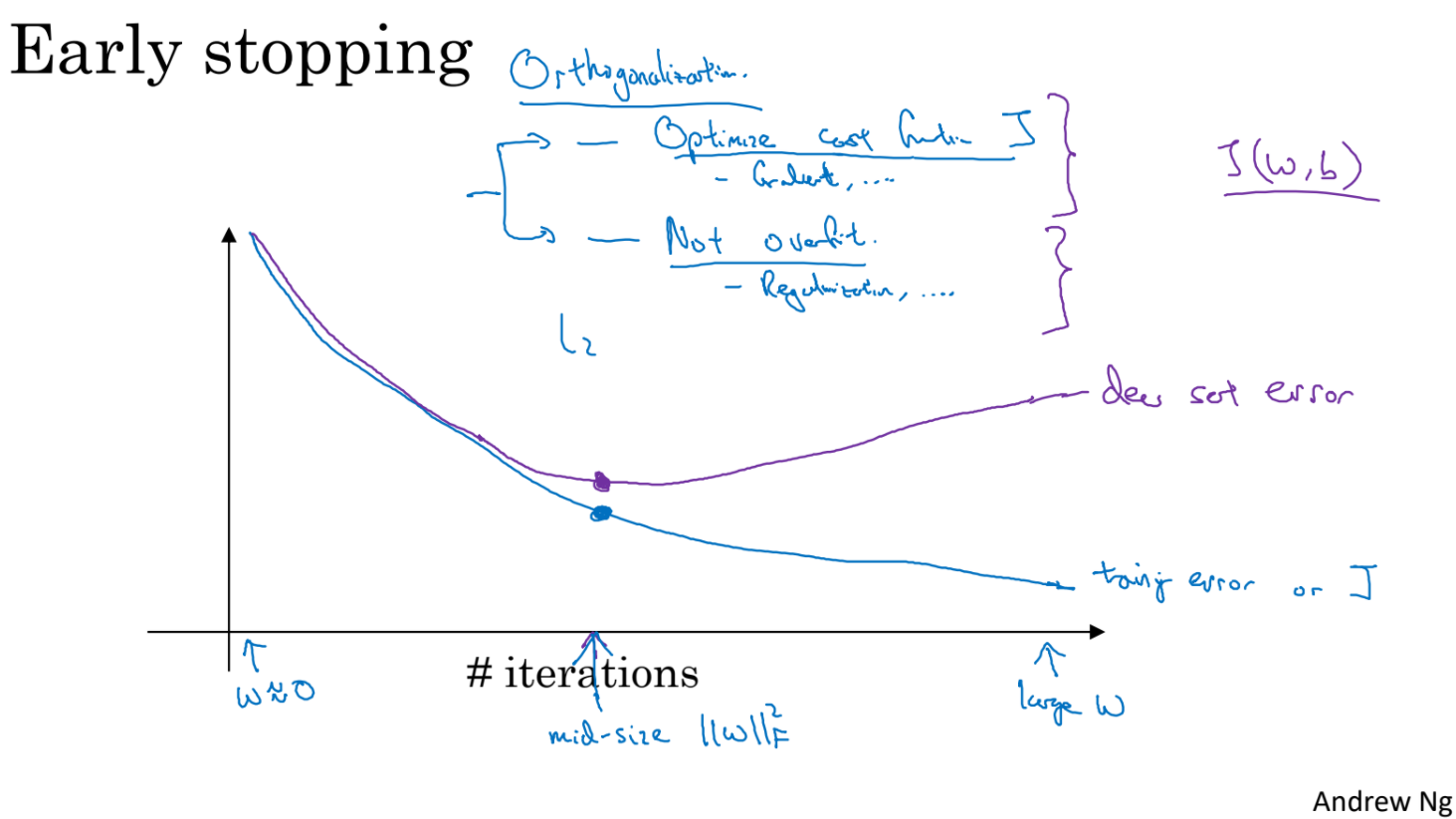
cost나 error가 iteration을 거치면서 어느 지점에서 test_error가 갑자기 상승한다면 overfitting 전에 training interation을 멈추는 것도 한가지 방법이다.
'ComputerScience > Machine Learning' 카테고리의 다른 글
| DeepLearning 2-2-1 (0) | 2021.10.06 |
|---|---|
| DeepLearning 2-1-2 (0) | 2021.10.05 |
| AI - 5. Fuzzy Logic (0) | 2021.10.01 |
| AI - 4. 전문가 시스템 (0) | 2021.09.17 |
| AI - 3. 탐색 응용 (0) | 2021.09.16 |



