1. XLNet

BERT에서는 sequence의 최대 길이 제한이 있었다. XLNet은 위 그림처럼 relative positional encoding을 적용함으로써 입력 sequence 길이 제한이 사라졌다.

GPT는 현재 상태에서 다음 단어만을 예측하는 일방향으로만 학습이 된다. 위 그림처럼 발 -> 없는 -> 말이 -> 천리, 이런식으로 말이다.

XLNet은 이와 달리 Permutation language modeling방식을 사용해 학습한다. 문장이 주어지면 토큰들의 모든 조합을 생성하고 그 섞인 모든 문장에 대해 다음 단어를 예측하도록 학습한다. [없는, 발, 말이, 천리, 간다] 로 섞인 문장에 대해 없는 -> 발 -> 말이 -> 천리 -> 간다 순으로 예측하도록 학습하는 것이다.
실제로 이런 새로운 시도가 당시 GLUE 벤치마크 SOTA를 달성하게 된다.
2. RoBERTa
기존 BERT의 학습방법만을 바꾼 버전이다. batchsize 학습시간, train data증가가 적용되었다. sentence길이도 늘리고 dynamic masking(똑같은 데이터에 masking을 10번 다르게 적용)을 적용했다. 그리고 next sentence prediction을 제거했다. 이 문제는 너무 쉬워서 오히려 성능을 하락시킨다고 보았다.
3. BART
bert와 gpt를 합치는 아이디어를 적용한 모델이다.

마스킹, permutation, rotation, deletion, infilling을 적용한 문장들을 올바르게 맞추도록 학습시킨다.
4. T-5
문제를 더 어렵게 정의함으로써 모델이 어려운 문제를 풀면서 자연어를 더 잘 이해하도록 한다.


하나의 토큰만 masking하는게 아니라 for inviting을 X로 바꿔버린다. 더불어 문장에 여러 토큰을 masking한다. 이렇게 만들어진 문장이 Input이 되고 <X>, <Y>를 맞추도록 학습된다.
BART처럼 Transformer Encoder-Decoder 구조를 가진다.
5. Meena
대화를 위한 언어모델이다. encoder block하나와 많은 decoder block을 겹쳐서 구성되어있다.
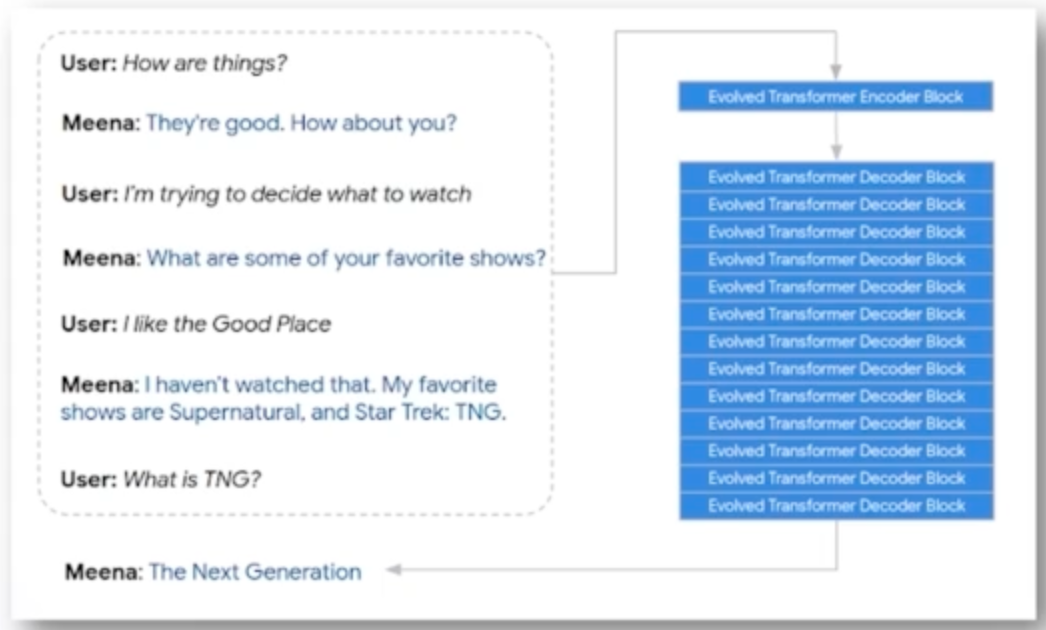
소셜미디어 데이터를 통해 학습되었고 end-to-end multi-turn 챗봇이다.
'boostcamp AI tech > boostcamp AI' 카테고리의 다른 글
| Multi-modal - LXMERT, ViLBERT, Dall-e (0) | 2024.01.18 |
|---|---|
| Controllable LM - Plug and Play LM(PPLM) (0) | 2024.01.18 |
| GPT-3/GPT-4 and Latest Trend 2 (0) | 2024.01.17 |
| BERT 복습 (1) | 2024.01.10 |
| NLP task : Relation Extraction (0) | 2024.01.03 |



