1. Relation Extraction?

문장의 단어(Entity)에 대한 속성과 관계를 예측하는 문제이다.
언어모델이 어떤 정보가 담긴 sentence을 이해할 수 있다면 그 sentence에 담긴 임의의 두 단어들의 관계를 맞출 수 있을 것이다.
sentence: 오라클(구 썬 마이크로시스템즈)에서 제공하는 자바 가상 머신 말고도 각 운영 체제 개발사가 제공하는 자바 가상 머신 및 오픈소스로 개발된 구형 버전의 온전한 자바 VM도 있으며, GNU의 GCJ나 아파치 소프트웨어 재단(ASF: Apache Software Foundation)의 하모니(Harmony)와 같은 아직은 완전하지 않지만 지속적인 오픈 소스 자바 가상 머신도 존재한다.
subject_entity: 썬 마이크로시스템즈
object_entity: 오라클
relation: 단체:별칭 (org:alternate_names)sentence, subject_entitiy, object_entity를 input으로 받아서 subject_entitiy와 object_entitiy의 관계를 맞추도록 한다.
총 30개의 relation class가 있고 이 중 하나로 분류하는 모델이 된다.
2. Evaluation Metric
결국은 30개의 관계 중 하나를 맞추는 분류 문제이기 때문에 f1-score를 활용할 수 있다. class별 샘플 수를 고려할 것이라면 Macro f1, 동일한 importance를 줄 것이라면 Micro f1을 사용할 수 있다.

class별 샘플 수가 imbalance하다면 각 샘플 별 AUPRC의 평균을 도입할 수 있다.
3. Model Input
Matching the Blanks : https://aclanthology.org/P19-1279.pdf
Typed Entitly Marker : https://arxiv.org/pdf/2102.01373.pdf
Semantic Typing : https://arxiv.org/pdf/2205.01826v1.pdf
[cls] 이순신 [sep] 조선 [sep] 이순신 장군은 조선 출신 이다 [sep]entity에 해당하는 토큰들을 [sep]으로 붙여서 맨 앞에 추가한 input을 모델에게 넣는다.
출력 텐서 중에 [cls]에 해당하는 벡터만 가져와서 classification layer를 통과하게 하고 원하는 개수의 class로 분류하도록 한다.
[cls] [ENT] 이순신 [/ENT] 장군은 [ENT] 조선 [/ENT] 출신 이다 [sep](Entity Maker 방식) 앞서 설명한 방식과 다르게 entity 앞 뒤로 [ENT]라는 speical token을 붙여줌으로써 추론할 관계의 객체 위치를 강조하는 방식으로 input을 만들 수도 있다.
[cls] [S:PERSON] 이순신 [/S:PERSON] 장군은 [O:OCUP] 조선 [/O:OCUP] 출신 이다 [sep]
[cls] @ * person * 이순신 @ 장군은 # $ ocup $ 조선 # 출신 이다 [sep](Typed entity marker 방식) 이번에는 entity 앞 뒤로 entity에 종류에 따라 다른 special token을 붙여서 input을 만들 수 있다.
혹은 speical token말고 특수기호를 활용해 entity 위치와 타입을 나타낼 수도 있다.

혹은 input은 그대로 두되, embedding layer에 entitiy의 위치 정보를 추가해주도록 만들어 볼 수도있다.
4. Domain Adaptation
reference : https://www.ruder.io/recent-advances-lm-fine-tuning/
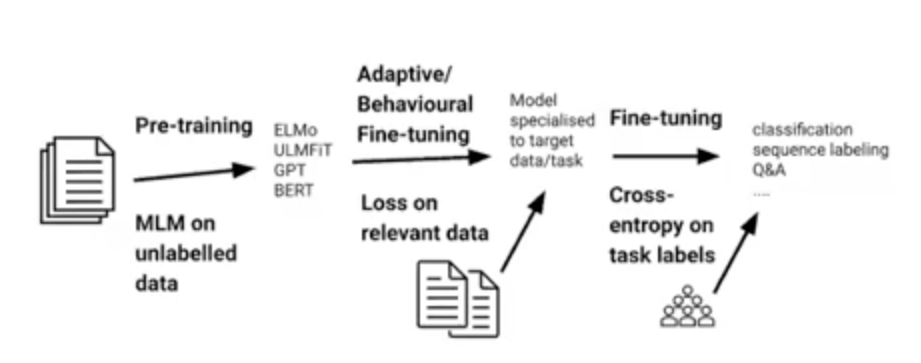
Pretrained model들은 뉴스, 일상 대화, 책, 위키피디아등에 대해 학습되어있다. 우리가 적용하려는 도메인은 klue/뉴스, klue/책에 대한 문장이 많다.
따라서 klue/뉴스, klue/책 문장들에 Mask Language Model 방식으로 mask를 씌워서 사전학습을 시켜서 보지 못한 문장들을 알고 있게 하고 그 다음 RE task로 finetuning을 하는 것이다.
5. Data augmentation
EDA : https://arxiv.org/abs/1901.11196
Backtranslation : https://arxiv.org/abs/1808.09381
Data augmented Relation Extraction with GPT-2 : https://arxiv.org/pdf/2004.13845.pdf
'boostcamp AI tech > boostcamp AI' 카테고리의 다른 글
| GPT-3/GPT-4 and Latest Trend 2 (0) | 2024.01.17 |
|---|---|
| BERT 복습 (1) | 2024.01.10 |
| Representation Learning & Self Supervised Learning (0) | 2024.01.02 |
| GPT-3 and Latest Trend (0) | 2024.01.01 |
| PyTorch Lightning Preview (0) | 2023.12.12 |



