1. GPT-2
모델 구조는 GPT-1과 크게 다를게 없다. 마찬가지로 다음에 오는 단어를 예측하는 LM(language modeling)으로 학습을 진행했다. 대신 gpt-1보다 더 깊고 사용한 데이터도 더 커졌다. byte pair encoding을 사용했다.
nlp task에 대해 생각해보면 어떤 문장이 주어졌을때, 어떤 주제에 속하는것 같은지? 긍,부정? 혹은 특정 단어의 품사? 등등 다양한 task를 떠올릴 수 있다.
어떤 task가 주어지던 똑같이 단어를 embedding vector로 변환하고 attention을 거치는 것은 똑같다.
그리고 잘 생각해보면 '이 영화 재밌다!' 뒤에 이 '이 문장이 긍정적인 것 같니?' 라고 덧붙이면 사실상 Question Answering 문제가 된다.
'나는 너를 좋아해'에 '너의 품사가 뭐야?' 라는 문장을 덧붙이면 마찬가지로 Question Answering 문제가 된다.
즉 multi task를 다 question answering으로 통합할 수 있다는 것이다.
gpt-1에서는 general한 학습이 끝나면 downstream task를 위한 (데이터, label)쌍을 가지고 fine-tuning을 수행했다.
GPT-2도 마찬가지로 그래도 되는데 놀라운 점은 fine-tuning을 하지 않아도 왠만한 성능을 확보할 수 있었다는 점이다.
즉 downstream task를 위한 데이터를 보지도 않았는데, 그냥 task를 설명하는 자연어를 input으로 받아서 문제를 푼다는 것이다.
2. GPT-3
GPT-2의 모델 사이즈를 아주아주 키웠다. (self-attention을 더 쌓았다.) 마찬가지로 데이터와 batch_size도 더 키웠다.
gpt-3는 gpt-2에서 보인 zero-shot setting에서의 가능성을 놀라운 수준으로 끌어올렸다.

zero-shot : 번역 task를 설명하는 문장 하나로 downstream task 수행
one-shot : task를 설명하는 문장 하나와 그 예시를 함께 자연어로 제공하여 수행
few-shot : task 설명 문장과 예시문장 여러 개
prompt : 모델이 뱉을 정답의 prefix
예시를 더 많이 줄 수록 좋은 성능이 나온다고 한다.
아무튼 중요한건 fine-tuning을 거치지도 않고 그대로 가져왔음에도 질문 자체에서 빠르게 내용을 습득하여 downstream task를 푼다는 것이다.
3. ALBERT : light BERT
앞에서 살펴본 pretraining model들은 점점 커져왔다. 더 많은 학습시간, 데이터, gpu를 필요로 하게 되었다.
ALBERT는 성능의 하락없이 모델 사이즈와 학습시간을 줄이는 시도를 한 모델이다.
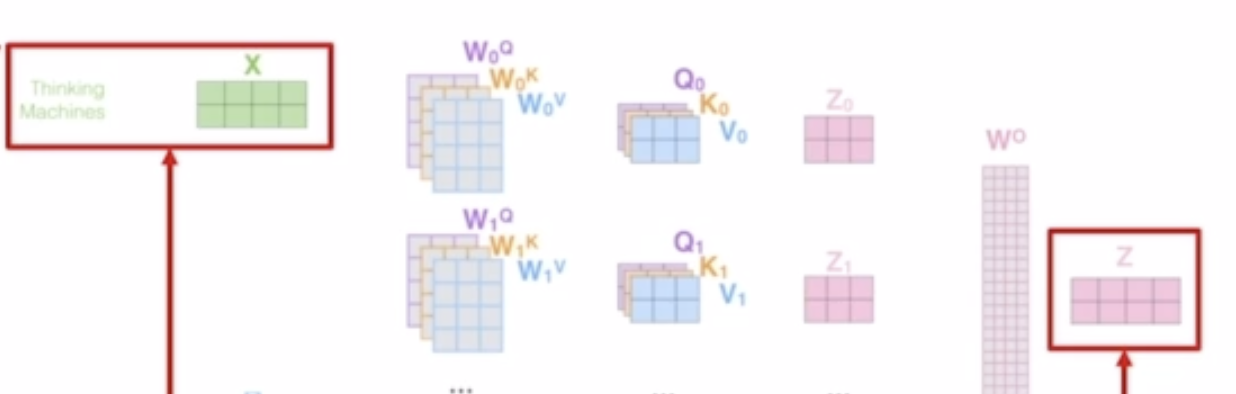
BERT에서는 residual connection이 있기 때문에 input 단어의 embeding vector와 attention을 거친 결과 Z vector의 크기와 같아야 한다.
embedding vector의 크기를 줄이면서도 모든 구조가 잘 동작하도록 할 수 없을까?라는 고민에서 Factorized embedding Parameterization이 등장했다.
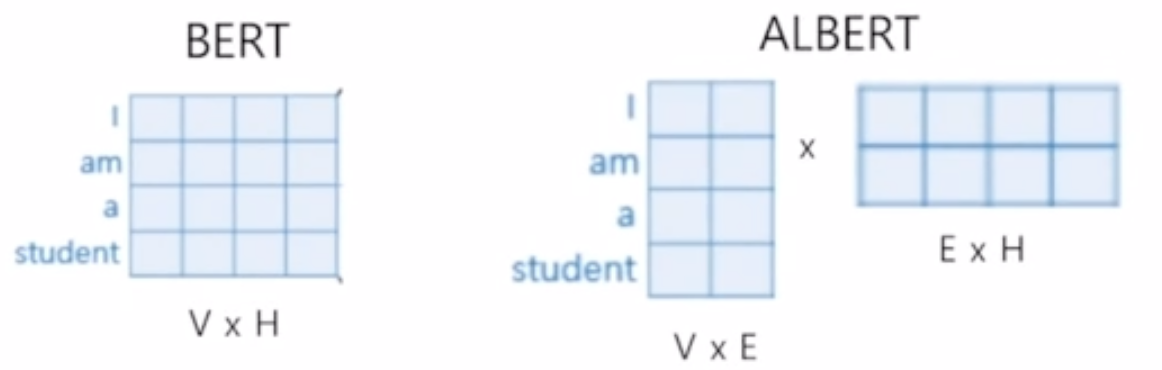
목표로하는 단어의 embedding size가 H라고 하자. 이를 E로 줄이고 바로 이어서 E->H로 늘려주는 Layer를 추가로 두는 형태로 바꿨다. 그럼 파라미터 수는 V*H 에서 V*E + E+H로 줄어든다.
cross layer parameter sharing
attention에 있는 파라미터는 head 개수만큼의 (Wq, Wk, Wv)와 Z를 도출하는 W가 있다. 만약 attention block이 하나 더 있다면 독립적인 h*(Wq, Wk, Wv)와 W가 있다.
이걸 모든 attention 층이 함께 공유하면 어떨까?라는 의문에서 출발하여
feed forward network W만 공유하면? 혹은 attention만 공유하면? 에 대해서 여러 실험을 수행했다.
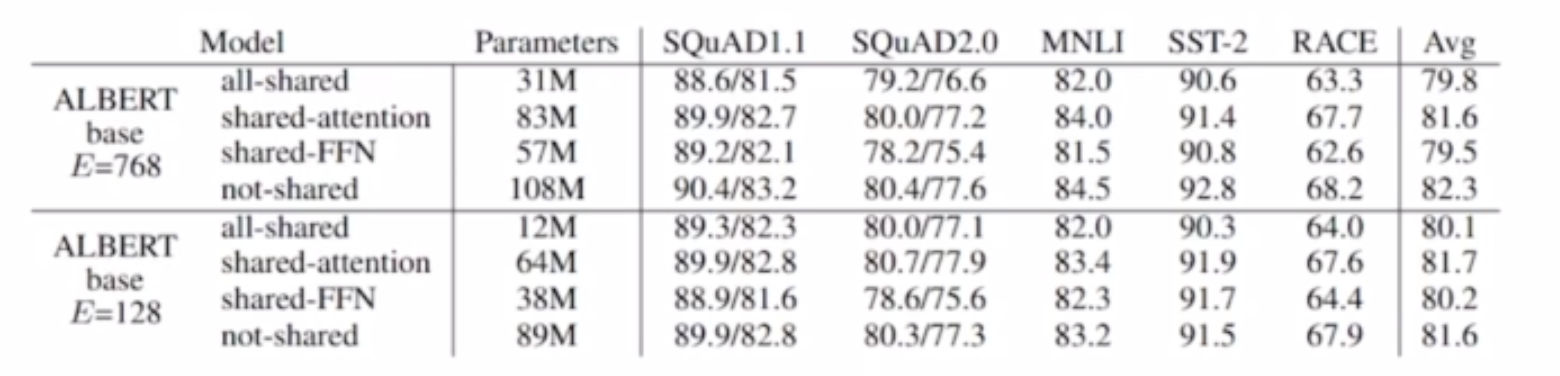
실제로 test 결과를 보면 성능 하락폭이 크지 않다 대신 모델 파라미터 수는 굉장히 줄었다.
마지막으로 살펴볼 특징은 sentence order prediction이다.
BERT는 [sep]을 기준으로 두 문장이 이어지는 것이 옳은가에 대한 next sentence prediction task를 학습하도록 되어있었다. 하지만 여러 연구를 통해 이 task가 별로 bert 성능에 유의미한 영향을 미치는것 같지 않다는 결론이 나왔다.

실효성이 없는 next sentence prediction task를 유의미 하도록 확장해서 학습을 시켰다. 두 문장들을 (옳은 순서, 혹은 역순서로) [sep]으로 묶어 input을 구성할 때, 이 두 문장이 "올바른 순서로 이어졌다 vs 틀린 순서로 이어졌다." 를 판단하도록 바꾸었다.
여기서 negative sampling을 했다는 것이 중요하다. 전혀 뜬금없이 다른 문서에서 (겹치는 단어도 없는) 문장을 뽑아다 붙이면 틀린 순서로 이어졌다를 예측하기가 매우 쉽다. 논리를 파악할 필요도 없어진다. 따라서 동일 문서에서 (겹치는 단어가 꽤 있는) 서로 다른 순서의 문장을 뽑아서 input을 구성했다. 모델은 자세히 속 뜻까지 분석하지 않으면 정답을 맞출 수 없다.
None(Mask만 사용), next sentence prediction 보다 더 좋은 성능을 SOP가 보여준다.
4. ELECTRA
얘는 기존의 pre-training model과는 좀 다르다.
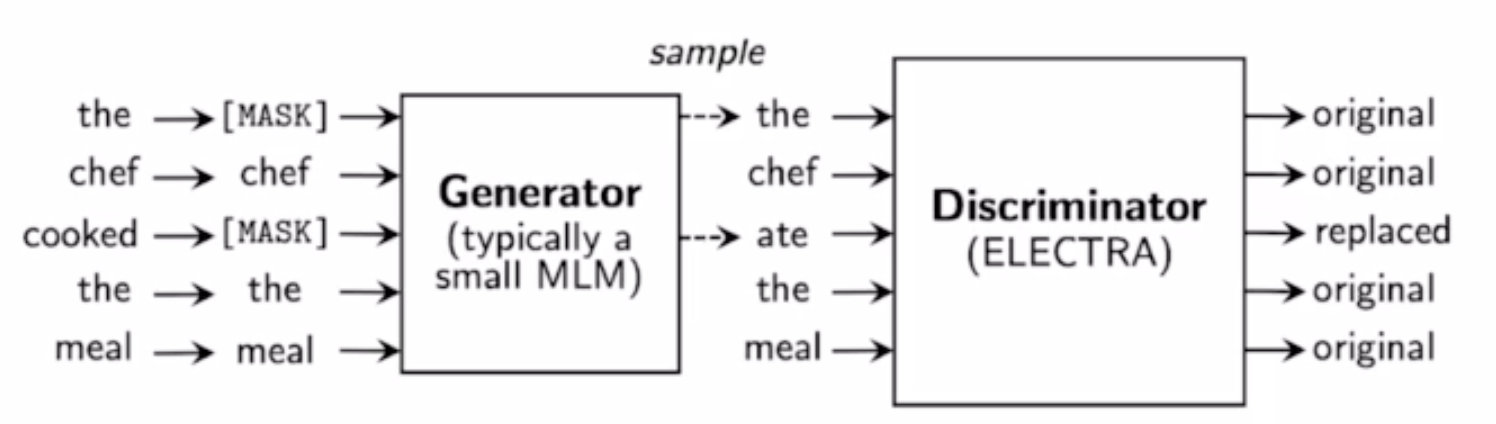
Mask로 가려진 문장을 받아서 generator가 mask에 해당하는 단어를 예측하면 Discriminator가 이게 '원래 단어인지' '예측된 단어인지' 맞추도록 한다. Generator는 사실상 계속 앞서 살펴본 BERT모델이다.
반면 Discriminator는 마찬가지로 attention을 쌓아올린 모델이지만 출력은 {original/replaced} 둘 중 하나의 형태를 띤다.
(GAN에서 착안한 방식이다.)
이 네트워크의 학습이 끝나고 나면 discriminator를 떼와서 base model로 사용한다. 이 ELECTRA를 가지고 다양한 task를 위해 fine-tuning하여 사용할 수 있다.
놀랍게도 BERT에 비해 (학습에 사용되는 계산량이 동일할 때) 좋은 성능을 보인다.
5. Next...
따라서 최근에는 pre-training model을 여러 방식으로 고도화 하여서 사용하려는 연구들이 많이 이루어지고 있다. 모델의 크기를 줄이면서도 성능은 유지하도록 많은 사람들이 모델 경량화 기법을 시도하고 있다.
- DistillBERT : Teacher model의 attention layer에서 나오는 softmax distribution과 student 모델의 것이 닮도록 학습을 수행한다. (teacher의 softmax distribution을 주입)
- TinyBERT : Teacher model의 Q,K,V, Embeding vector, W등 모든 파라미터와 중간 결과물들을 student model의 것들이 닮도록 학습하는 기법이다. 두 모델에서 나온 값들의 Mean squared error를 줄이는 방향으로 학습한다.
6. Fusing Knowledge Graph
BERT가 놀라운 성능을 보여주긴 하나 약점이 존재한다. '꽃을 밭에 심는다'는 문장을 보면 문맥과 단어 사이의 관계를 잘 판단하는데 여기에 '땅을 무엇으로 팠을까?'라는 질문을 한다면 헤매는 모습을 보인다.
소위 상식으로 인간에게는 고려되는 이런 지식은 knowledge graph로 표현이 된다. 이것을 pretraining model에 학습에 활용하려는 시도들도 있다.
'boostcamp AI tech > boostcamp AI' 카테고리의 다른 글
| PyTorch Lightning Preview (0) | 2023.12.12 |
|---|---|
| Introduction to NLP task (0) | 2023.12.12 |
| Self-Supervised Pre-training Model (GPT-1, BERT) (0) | 2023.12.07 |
| Transformer - Multi-Head attention (2) | 2023.12.06 |
| Transformer - self attention (1) | 2023.12.06 |



