1. Relation
- 데이터의 여러 속성(attribute)들을 column으로 묶어서 관계들을 table로 정의한다.

2. Atrribute
- table의 각 column에 해당하는 attribute가 존재한다.
- ID가 될 수 있는 값들을 모은 집합을 domain of ID(attribute)라고 한다. 예를 들면 domain of ID = {00000 ~ 99999}이 된다.
- relational database의 attribute가 되기 위해서는 atomic한 조건이 요구된다. attribute는 반드시 단일값이여야 한다는 것이다. 즉 위의 예시에서 Wu라는 교수님이 Finance와 Music을 겸직해서는 안된다.
- 만약 겸직하는 교수님을 relation db로 표현해야 한다면 table의 schema를 바꾸어야 할 것이다.
- attribute의 값을 모르는 경우 혹은 속성이 없는 경우에 null을 넣으면 된다.
- null은 data들끼리의 연산을 복잡하게 만든다. 따라서 null값이 적게 등장하는 schema를 정의하도록 해야한다.
3. Schema, Instance
- table을 구성하는 attributes columns의 구조를 schema라고 한다.
- db의 논리적인 구조를 schema라고 한다.
- instructor (Id, name, dept_name, salary)를 schema라고 한다.
- 이 테이블에 실제로 들어가 있는 record들을 instance라고 한다.
- 특정 시점의 data의 값을 snapshot이라고 한다. instance들의 값이 시시각각 변하기 때문에 순간의 instance들의 값을 snapshot이라고 부른다.
- table에 있는 tuple들은 순서관계가 존재하지 않는다.
4. Cartesian-Product
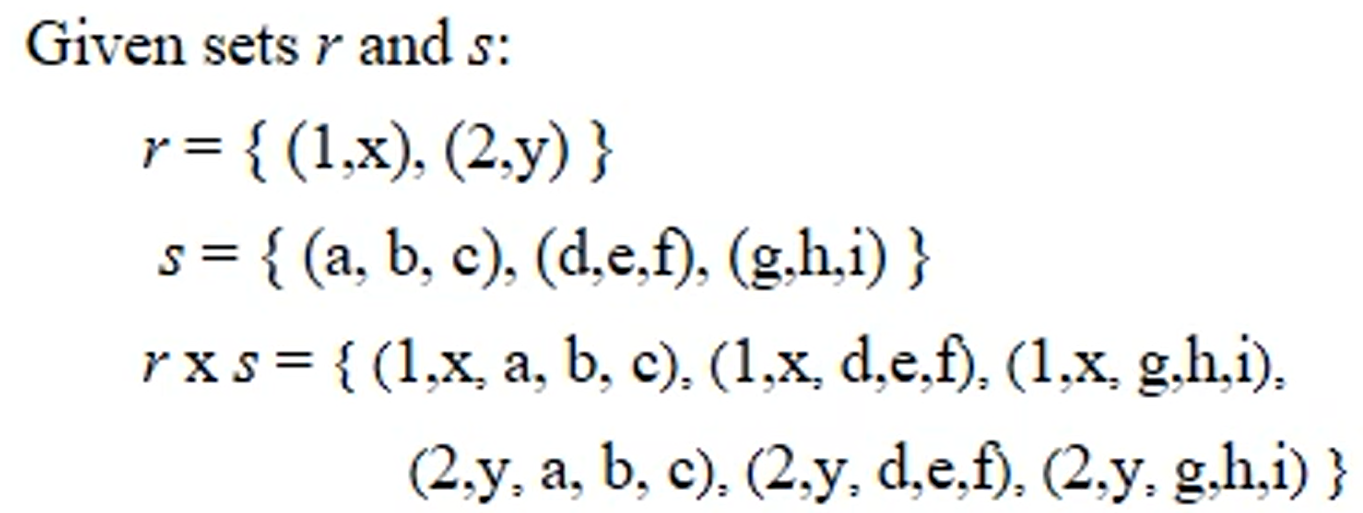
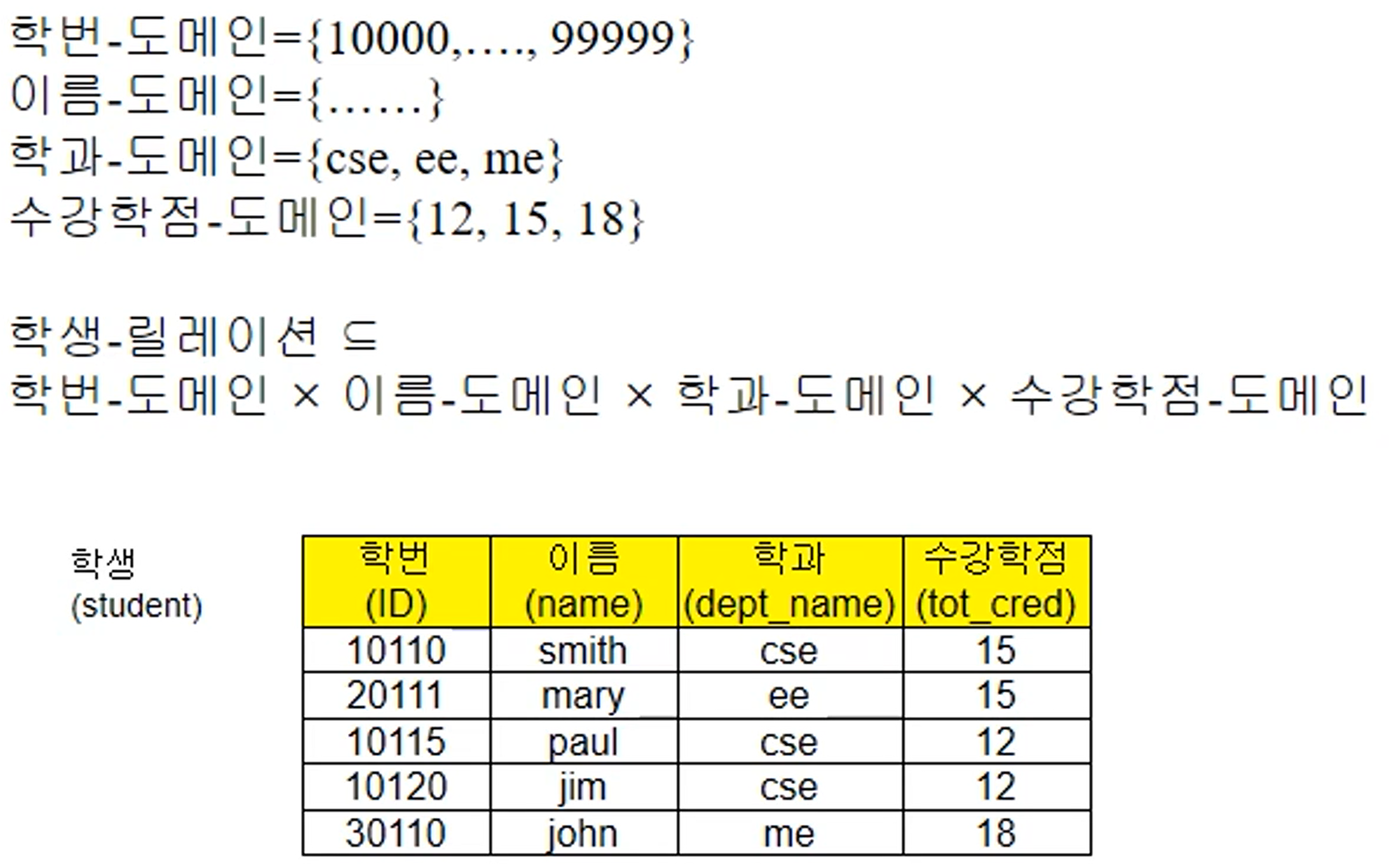
- student relation은 네개의 domain끼리의 catesian-product의 부분집합이다.

- 즉 student relation은 위와 같이 집합으로 표현할 수 있다.
'ComputerScience > Database' 카테고리의 다른 글
| DB - 6. More SQL statements(1) (0) | 2021.09.29 |
|---|---|
| DB - 5. Schema Diagram, Relational Algebra (0) | 2021.09.15 |
| DB - 4. Keys (at relational DB) (0) | 2021.09.15 |
| DB - 2. Basic SQL statements (0) | 2021.09.08 |
| DB - 1. Introduction (0) | 2021.09.01 |



