extraction-based MRC는 답변의 위치를 본문에서 찾는다. 즉 정답 토큰의 위치를 예측한다. 그래서 bert와 같은 ,seq2seq이 아닌, PLM에 Classifier를 부착해서 모델을 구성했다.

반면 generation-based mrc는 답변을 생성하는 task이다. 정답 텍스트 자체를 예측한다. 따라서 auto regressive 형태로 모델이 정답을 출력하게된다. seq2seq PLM 구조를 활용한다. (ex. bart, T5)
1. Pre-processing

extraction-based mrc에서는 정답의 위치를 나타내는 answer_start 정보가 중요했다. 하지만 생성방식에서는 이를 제외한 question, answer면 충분하다.
우리가 생성모델을 사용할 것이기 때문에 extraction-based mrc와 preprocessing단계에서 차이를 보이는 요소들이 몇가지 있다.
우선 T5같은 경우는 sentencePiece tokenizer를 사용하는 점과 token type_id를 사용하지 않는다는 점이 있다. special token의 쓰임도 다를 수 있다. 따라서 PLM을 선택했다면 이와 같은 차이들을 잘 살펴봐야 한다.
2. Models
Transformer의 decoder를 활용하는 gpt, 혹은 둘 다를 사용하는 bart, T5 등을 사용할 수 있다.

meta에서 만든 bart의 설계도면을 가져온 그림이다. 각 token에 해당하는 embedding 값을 vocab_size로 차원변환을 하는 Linear layer를 거치게 하여 가장 높은 확률의 단어를 순차적으로 선택해나간다.
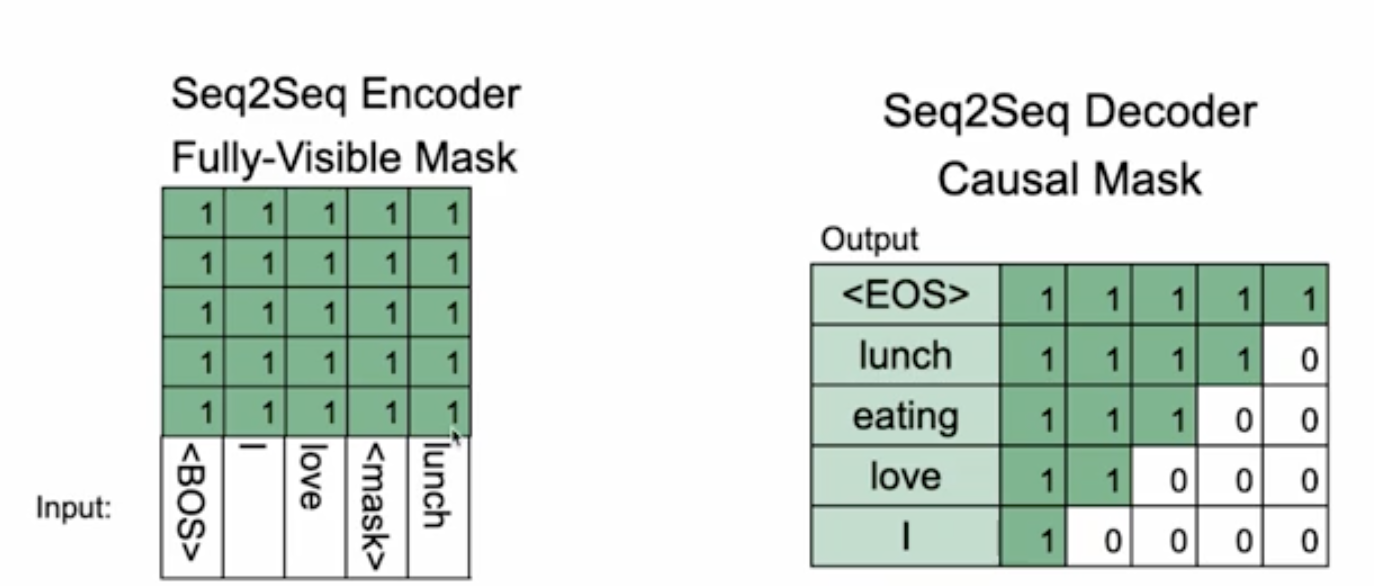
auto regressive model이기 때문에 decoder에서는 매 토큰마다 반복적으로 결과를 출력하며 input에서 현재 토큰 뒤에 있는 토큰들을 가리는 mask가 적용된다.

google에서 만든 T5의 모습이다. T5는 모든 자연어 task의 문제를 text input하나로 만들어버린다. 번역하는 문제의 경우 'translate En to German: That is good' 으로 넣어버리고. 요약의 문제의 경우 '요약해줘: ㅇㅇㅇ는ㅇㅇㅇ며 ㅇㅇ다' 처럼 하나의 text input으로 넣어서 학습시킨다. 즉 instruction을 통해 multi-task learning을 하는 셈이다.
downstream task를 위해 fine-tuning할 때 prefix를 사용하는 이런 방식을 제시함으로써 text-to-text 라는 분야가 생겨났다.
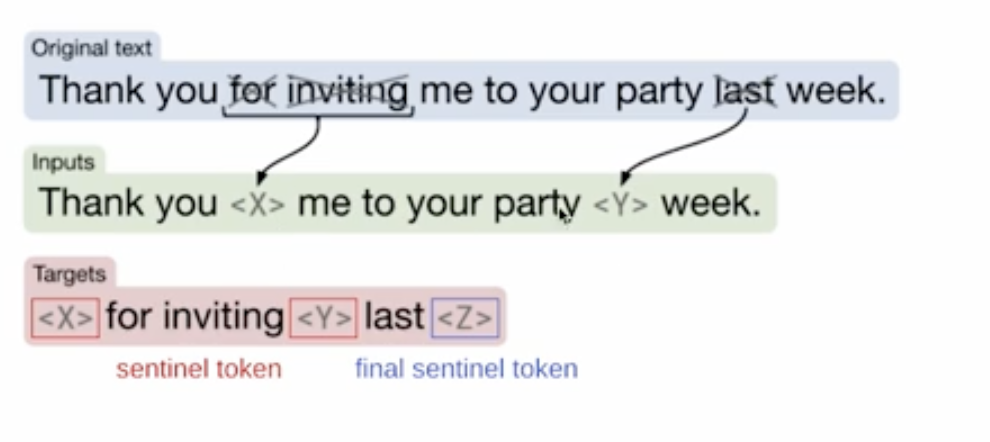
bart의 경우에서는 노이즈가 잔뜩 첨가된 문장을 복원하도록 학습했다. 노이즈가 있든 없든 원본 문장을 전부 생성하는 것이 비효율적이다라는 측면을 T5에서는 개선을 했다.
T5에서는 phrase혹은 어떤 token을 지워서 input을 만든다. 모델은 그 지워진 부분에 해당하는 단어만 예측한다.

T5에서 나아가 multi-language를 커버하기 위해 다국어 데이터로 학습된 mT5 모델도 있다.
3. Post-processing

autoregressive란 hidden vector를 vocab_size로 변환하여 softmax를 거쳐 만들어낸 distribution에서 가장 높은 확률의 단어를 sampling하고 이 과정을 반복하는 과정을 말한다. 이렇게 반복적인 과정으로 하나씩 생성한 token들을 합치는 것이 Ideal한 답변을 보장하지 않는다.

따라서 ideal한 문장 생성을 위한 search 방법들을 적용하여 문장을 완성한다.
'boostcamp AI tech > boostcamp AI' 카테고리의 다른 글
| Passage Retrieval - Dense Embedding (0) | 2024.02.16 |
|---|---|
| Passage Retrieval - Sparse Embedding, TF-IDF (1) | 2024.02.14 |
| Extraction-based MRC (0) | 2024.02.06 |
| Intro to MRC(Machine Reading Comprehension) (2) | 2024.02.05 |
| Boostcamp AI - week14, 15, 16 (0) | 2024.02.05 |



