0. Cross Lingual Transfer Learning
한국어 BERT를 만든다고 하면 비용과 시간이 많이 들것이다. 그렇다고 기존의 큰 multilingual pretrain model을 쓰기에는 한국어에서 성능이 기대보다 좋지 않을 수 있다. 그래서 영어 BERT를 활용해서 한국어에서도 잘 하도록 할 수 없을까?에 대한 시도이다. 언어가 갖는
공통점을 극대화 시켜보려는 방법이다.

encoder 앞뒤에 adaptation layer를 추가하고 encoder는 freeze시킨다. 새로 추가된 layer는 영어-한국어의 차이를 학습하게 되는 셈이다. 이렇게 step1이 끝나면 frozen시킨 encoder도 풀어주고 다시 한국어 문장들로 학습을 시킨다.
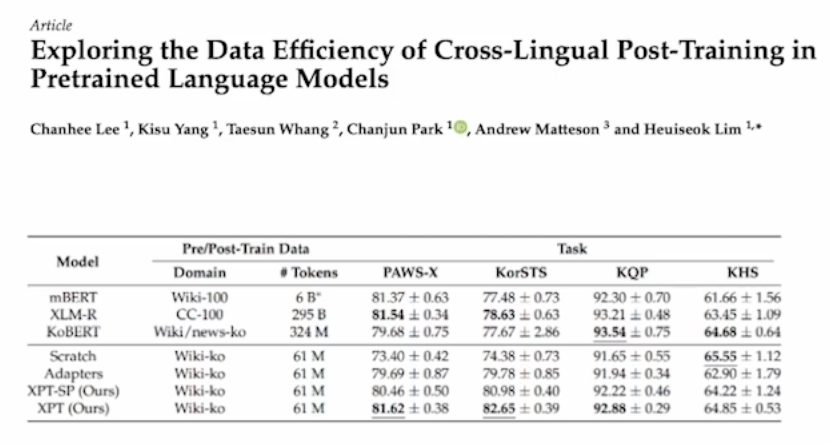
실험을 해보니 상대적으로 굉장히 적은 양의 한국어 데이터로 위와 같이 학습한 모델이 아예 처음부터 한국어를 학습한 모델보다 비슷하거나 좋았다고 한다.
1. Iterative Back-Translation for Neural Machine Translation
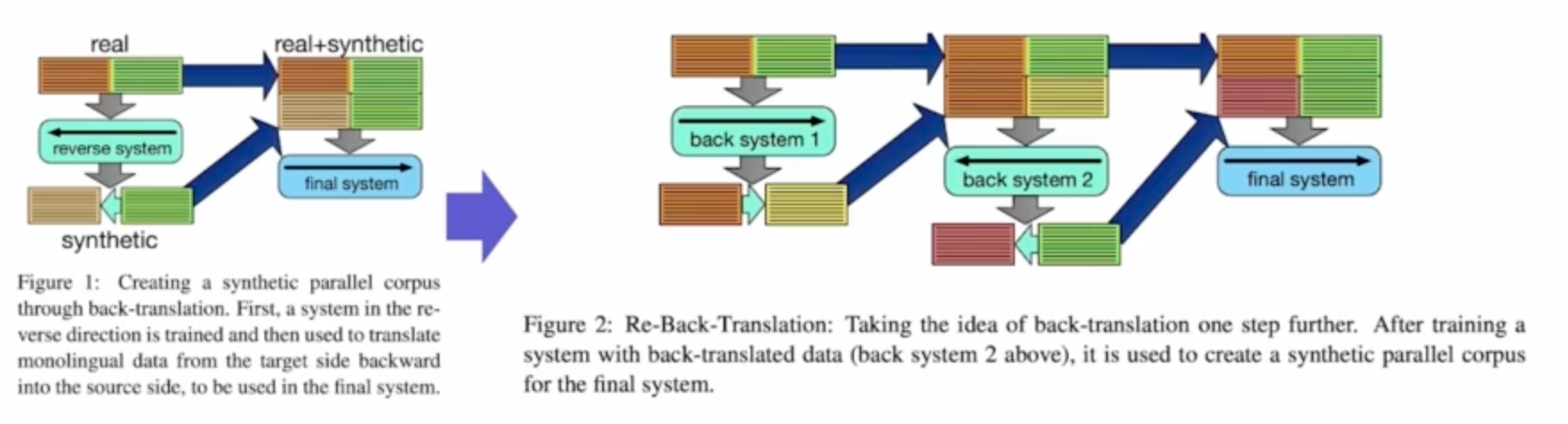
back-translation은 한국어 -> 영어 -> 한국어 순으로 번역하여 한국어 데이터의 증강을 하는 방법이다.
Iterative back-translation은 단순히 이 과정을 한번 더 하는 것이다.

실험을 통해 이 방법이 효과가 있음을 보였다.
2. How Effective is Task-Agnostic Data Augmentation for Pretrained Transformers?
back-translation이나 Easy Data Augmentation같은 task-agnostic한 증강 기법들이 lstm, cnn에서는 효과가 있었으나 BERT같은 Transformer계열에는 효과가 없다는 것을 보인 논문이다.

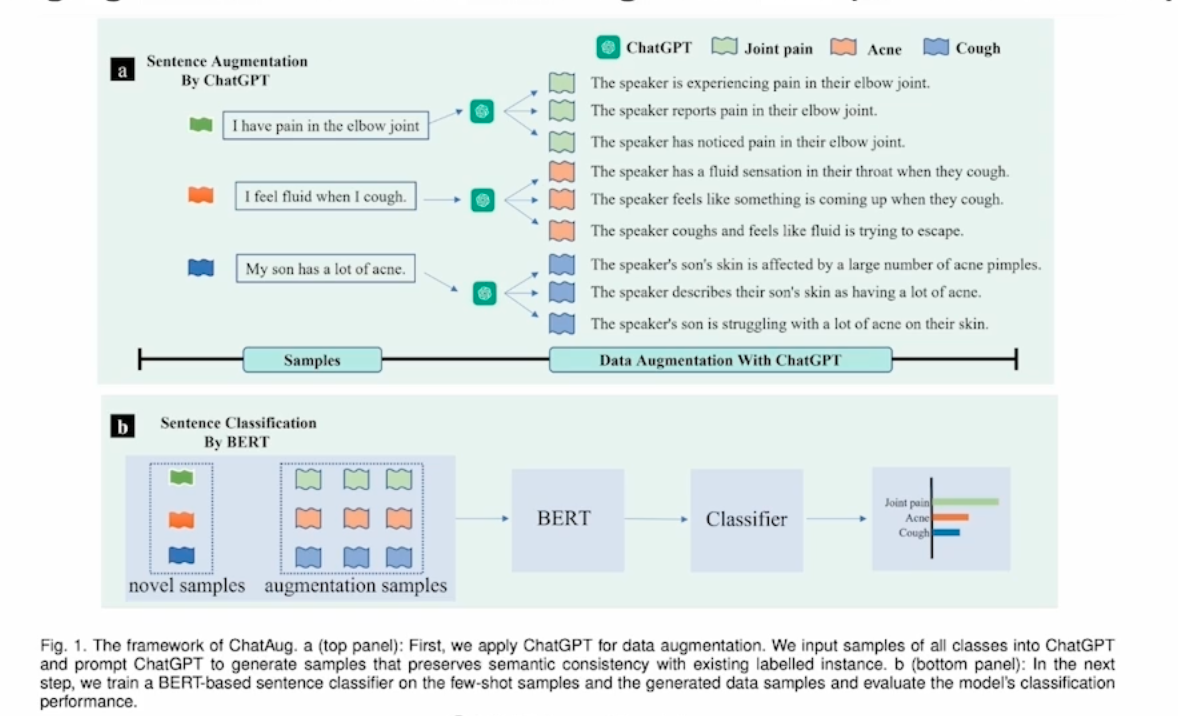
3. ChatAug : Leveraging ChatGPT for Text Data Augmentation
chatGPT를 사용한 증강 방법을 제안한 논문이다.
4. Parallel Corpus Filtering
학습에 도움이 되지 않는다고 판단되는 샘플들은 제외시키는 방법을 filtering이라고 한다. 예를들어 문장이 너무 짧거나 긴 경우, 혹은 special token들이 너무 많이 포함된 문장 같은 것을 걸러내는 작업이다.
- Rule Based
- NMT Based : Sentence Embedding(LM, NMT, LASER), Model Cross Entropy, Sentence Classifier(Pseudo-negative sample, judging quality of sentence pair)
5. Prompting Methods in Natural Language Processing
요즘은 fine-tuning과 더불어 prompt tuning을 통해 모델의 성능을 향상키기고 있다.

6. Prompt Programming for Large Language Models : Beyond the Few-Shot Paradigm
본 논문에서는 prompt생성을 위한 prompt를 제안한다. 이를 metaprompt라고 한다.

'boostcamp AI tech > boostcamp AI' 카테고리의 다른 글
| Boostcamp AI - week14, 15, 16 (0) | 2024.02.05 |
|---|---|
| Multi-Modal AI Dataset (0) | 2024.01.24 |
| NLP Datasets 2 (0) | 2024.01.23 |
| NLP Datasets 1 (0) | 2024.01.23 |
| Intro to Data Centric AI (0) | 2024.01.22 |



