1. bottom up parsing
LL parsing에서는 여러 문제점이 있었고 결국엔 모든 문법을 검사할 수 없었다. 반면 bottom up parsing은 훨신 효율적으로 "모든 문법"을 검사할 수 있다. syntax error도 backtracking이 없기 때문에 훨씬 빠르게 검사할 수 있다. 게다가 top down 에서는 EBNF를 사용했지만 bottom up 은 the larger class of grammar인 BNF로도 충분하다.
bottom up 에서는 right sentential form에서 RHS 부분을 찾아서 그 이전 right sentential form으로 바꾸는 방식으로 reduce한다. right most derivation의 역순으로 전개해나간다.
다시말해 current sentential form에서 substring을 찾는 과정이다.

S에서 시작해서 여러번의 remove를 거쳐 αAw가 되고 여기서 remove를 한번 했을때 αβw가 된 상황에서 β를 handle이라고 한다.
bottom up parsing에서는 이 β를 A로 바꿔서 reduce를 한다.

remove 한번이면 simple phrase, 여러번이면 phrase이다.
bottom up parsing은 right sentential form에서 leftmost simple phrase(handle)을 pruning해가는 방식이다.
2. LR parsing example
E -> E + T | T
T -> T * F | F
F -> (E) | idid + id * id 를 bottom up 방식으로 parsing 해보자.
먼저 right most derivation으로 전개를 해보자.
E -> E + T
-> E + T * F
-> E + T * id
-> E + F * id
-> E + id * id
-> T + id * id
-> F + id * id
-> id + id * id
이 과정을 역순으로 따라가보자.
id + id * id -> F + id * id * 여기서 leftmost simple phrase(handle)은 id
-> T + id * id * 여기서 leftmost simple phrase(handle)은 F
-> E + id * id * 여기서 leftmost simple phrase(handle)은 T
-> E + F * id * 여기서 leftmost simple phrase(handle)은 id
-> E + T * id * 여기서 leftmost simple phrase(handle)은 F
-> E + T * F * 여기서 leftmost simple phrase(handle)은 id
-> E + T * 여기서 leftmost simple phrase(handle)은 T*F
-> E * 여기서 leftmost simple phrase(handle)은 E+T

3. LR parsing - shift reduce algorithm
bottom up 방식의 대표적인 알고리즘이다.
S -> E
E -> T + E
E -> T
T -> intLR parser로 int + int + int를 전개를 해보자. 이때 버퍼(stack)를 하나 두고 최종 sentence에서 하나씩 버퍼로 shift한다.
stack에 현재 parser의 상태, history를 저장한다.
// rightmost derivation, 여기에 역순으로 bottom up parsing이 수행될 것
S -> E
-> T + E
-> T + T + E
-> T + T + T
-> T + T + int
-> T + int + int
-> int + int + int

parser의 state은 이렇게 저장된다.
0 : start of stack
$ : parse end
LR parser는 table driven 방식이다.
parser의 state과 next token을 받아서 parser의 행동을 반환하는 ACTION
reduction action이 끝나고 stack에 어떤 state를 push해야 하는지 알려주는 GOTO가 있다.
문법이 주어지면 아래처럼 table이 생성된다. 이걸보고 parser가 parsing을 수행하는데 모습은 아래와 같다.
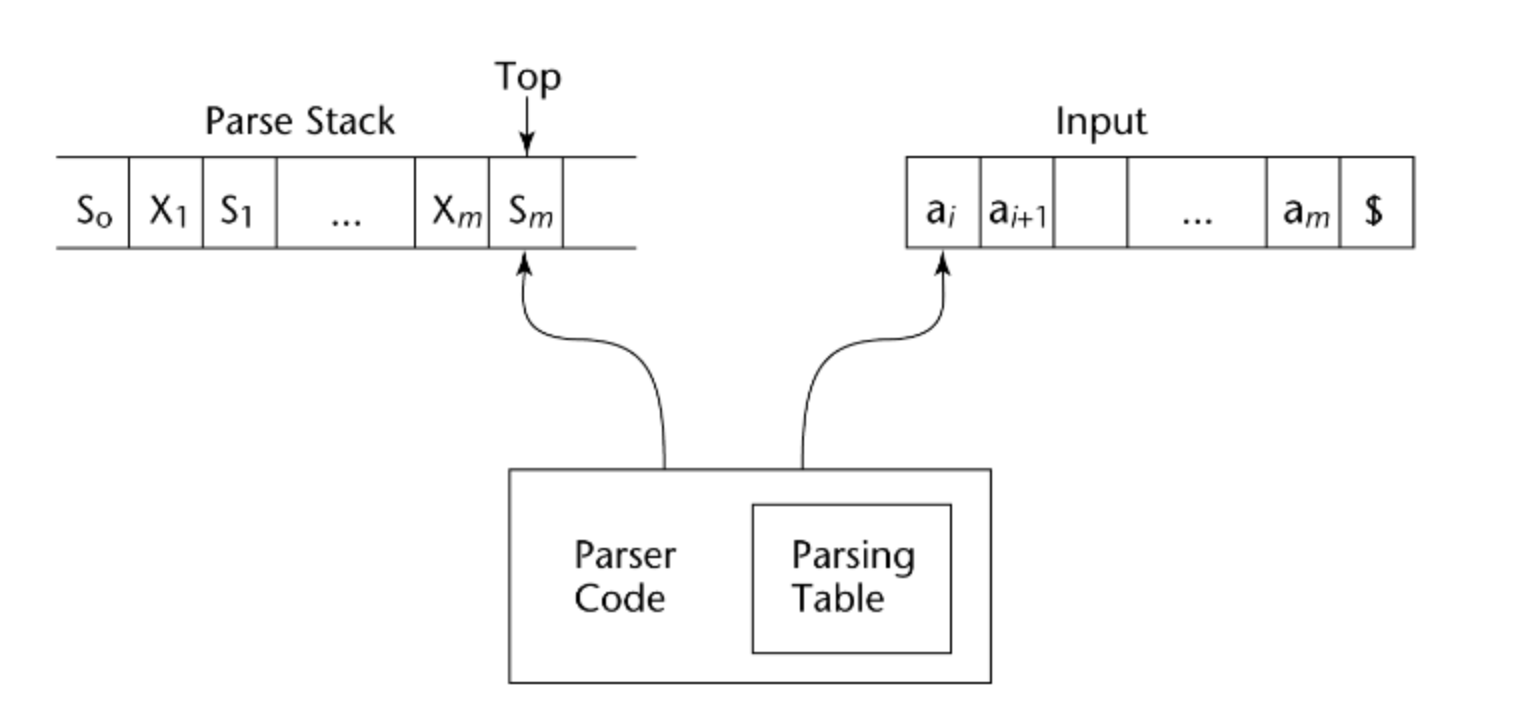
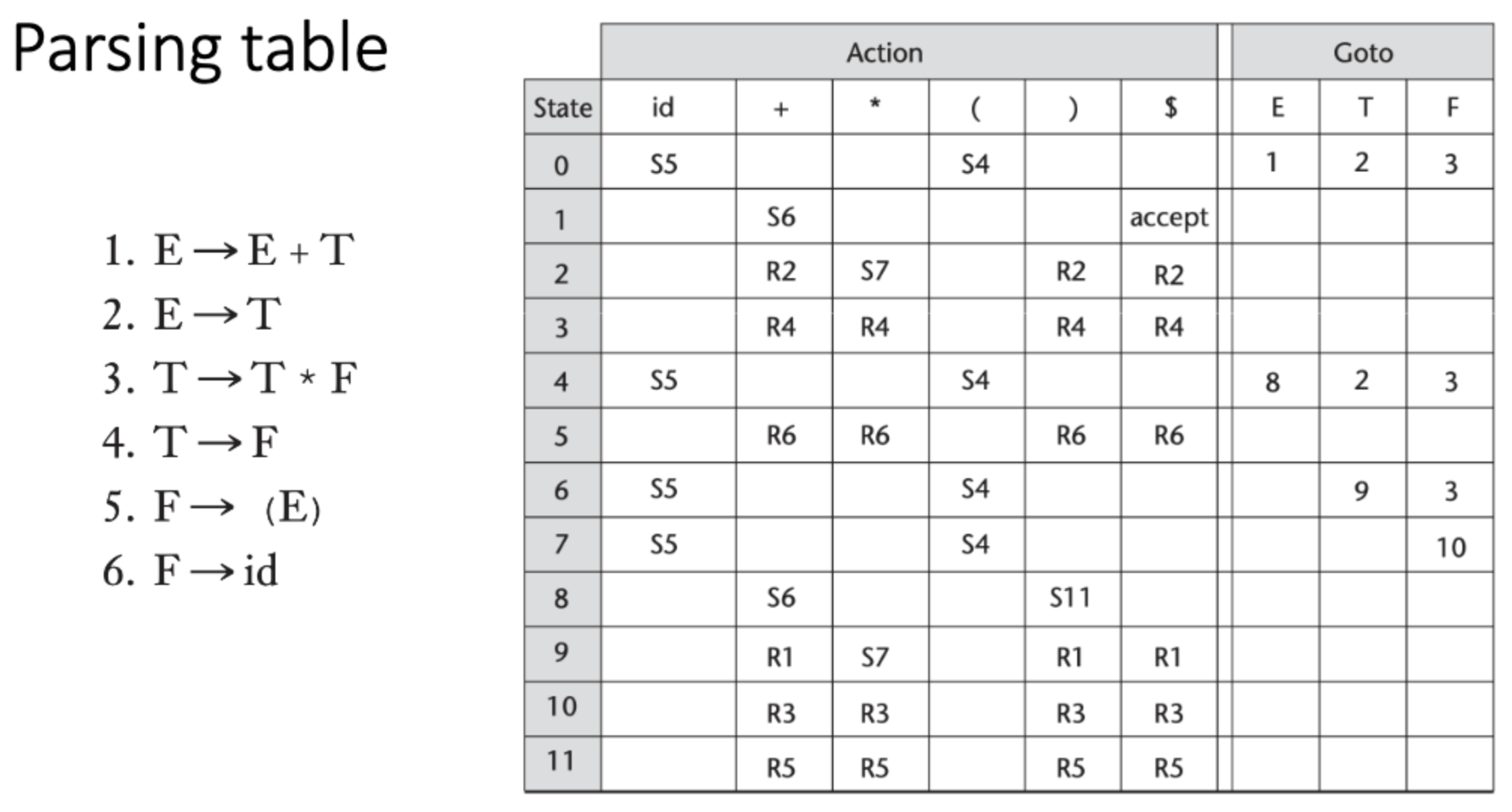
자 이런 문법이 있다고 해보자. tool을 통해 table도 함께 제공된다.

1. stack의 초기값은 0, 현재 parser의 state은 0이다. 테이블을 보니 현재 0 state에서 Input이 id이면 shift 5 action이 정해져 있다. id를 stack에 shift하고 parser의 상태 5도 집어넣는다.
2. 현재 parser의 state은 5이다. input에 + 가 대기중이므로 테이블을 보면 R6라고 되어있다. 6번 rule을 사용해서 reduction을 진행한다. id를 F로 바꾼다. 0id5 -> 0F가 된다. 현재 parser의 상태 0, top에는 F가 있으므로 GOTO[0,F]로 다음 state 3으로 이동하고 stack에 3까지 집어 넣는다.
3. 현재 parser의 state은 3이다. input에 +가 대기중이므로 테이블을 보면 R4라고 되어있다. 4번 rule을 적용해서 reduction을 진행한다. F를 T로 바꾼다. 0F3 -> 0T가 된다. 현재 parser의 상태 0, top에는 T가 있으므로 GOTO[0,T]로 다음 state 2로 이동하고 stack에 2까지 집어 넣는다.
4. 현재 parser의 state은 2이다. input에 +가 대기중이므로 테이블을 보면 R2라고 되어있다. 2번 rule을 적용해서 reduction을 진행한다. T를 E로 바꾼다. 0T2 -> 0E가 된다. 현재 parser의 상태 0, top에는 E가 있으므로 GOTO[0,E]로 다음 state 1로 이동하고 stack에 1까지 집어 넣는다.
5. 현재 parser의 state은 1이다. input에 +가 대기중이므로 테이블을 보면 S6라고 되어있다. +를 shift해서 집어넣고 현재상태가 될 6도 함께 집어 넣는다.
6. 현재 parser의 state은 6이다. input에 id가 대기중이므로 테이블을 보면 S5라고 되어있다. id를 shift해서 집어넣고 현재상태가 될 5도 함께 집어 넣는다.
7. 현재 parser의 state은 5이다. input에 *가 대기중이므로 테이블을 보면 R6라고 되어있다. 6번 rule을 적용해서 reduction을 진행한다. id를 F로 바꾼다. 0E1+6id5 -> 0E1+6F가 된다. 현재 parser의 상태 6, top에는 F가 있으므로 GOTO[6,F]로 다음 state 3로 이동하고 stack에 3까지 집어 넣는다.
........
end. 맨 마지막에, parser의 state은 1이다. input에 $가 대기중이므로 테이블을 보면 accept라고 되어있다. 종료
'ComputerScience > Principle of programing language' 카테고리의 다른 글
| PL8. Names, Bindings and Scopes (0) | 2023.11.20 |
|---|---|
| PL6. Syntax Analysis - top down parsing (0) | 2023.10.06 |
| PL5. Dynamic semantics : Axiomatic (0) | 2023.10.04 |
| PL4. Dynamic semantics : Operational, Denotational (0) | 2023.09.27 |
| PL3. Static semantic (0) | 2023.09.15 |



