1. Web
Web은 우리가 너무 잘 알고 있다. web page는 이미지, 음성, html file등 여러 objects를 포함하고 있다.
각 object들의 address를 URL로 나타낸다.

2. HTTP(hypertext transfer protocol)
거의 모든 웹 브라우저, 웹 서버는 http 프로토콜을 사용한다.
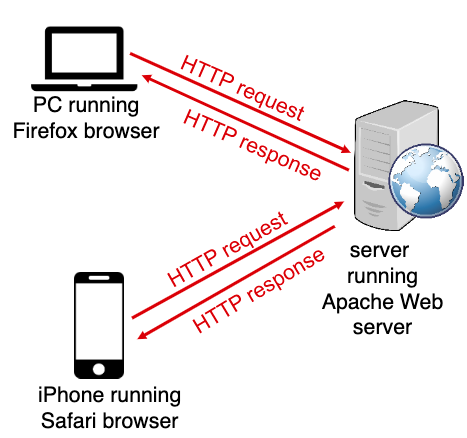
client/server model에서 http동작을 살펴보자.
client는 browser를 통해 web server에게 object를 달라고 http요청을한다.
서버는 그 요청의 응답으로 해당 object를 http를 통해 보내준다.
http는 기본적으로 tcp를 사용한다. 따라서 client가 먼저 서버와의 TCP connection을 시도한다. 이때 보통 port는 80을 사용한다.
서버가 TCP connection을 accept하면 사용자의 browser(HTTP client)와 웹서버(HTTP server)간의 http message 교환이 이루어진다.
전송이 끝나면 TCP connection은 닫힌다.
HTTP 프로토콜은 과거 client요청에 대해서 아무 정보도 기억하지 않는다. 이래서 HTTP가 Stateless라고 한다.
따라서 특정 정보를 기억하고 싶다면 browser 혹은 web server에서 따로 cookies, caches등을 사용한다.
3. TCP connection management
http가 tcp connection을 관리하는 두 가지 방법이 있다.
Non-persistent HTTP
한번의 TCP connection으로는 한개의 object만 보낼 수 있다.
따라서 한 웹사이트가 10개의 이미지를 포함하고 있다면 10번의 TCP connection이 이루어져야 한다.
요즘 web browser는 10개의 TCP connection을 한번에 연결하고 동시에 병렬적으로 10개의 이미지를 받는다.

10개의 이미지를 포함하는 웹사이트라면 1부터 6까지의 과정을 10번 반복해야 한다.

non-persistent HTTP에서 총 response time을 구하려면 RTT를 생각하면 된다.
tcp연결, http요청을 위한 시간과 파일 전송 시간을 고려하면 총 응답시간은 2 * RTT + transmition time(L/R) 가 된다.
총 10개의 이미지를 받아야 한다면 20 * RTT가 소요된다. (물론 parallel로 처리한다면 훨씬 시간을 단축할 수 있다)
Persistent HTTP
client, server사이에서 단 한개의 TCP connection으로 여러개의 object를 주고받을 수 있다.
뒤에서 더 깊게 다루겠지만 tcp throughput은 점점 커지다가 congestion control때문에 평균을 유지한다. 따라서 여러개의 파일을 전송할때 점점 빠른 속도를 경험할 수 있다.
4. HTTP request message
HTTP 요청 메시지는 전부 사람이 읽을 수 있도록 ASCII로 되어있다.
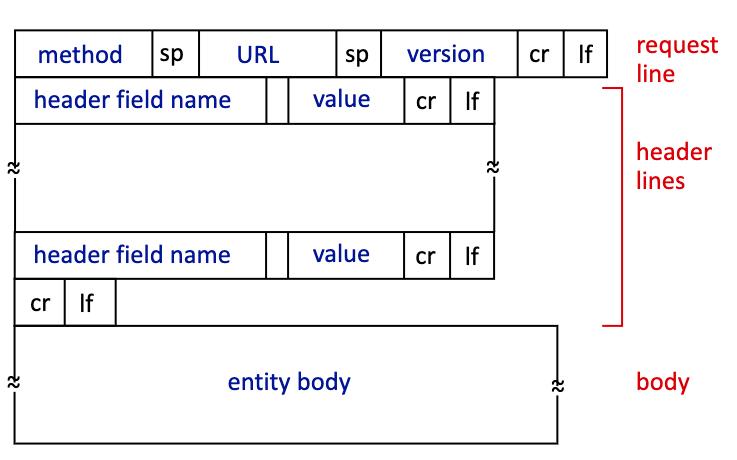

일반적인 요청 format은 이렇게 되어있다.

옛날에는 서버로 데이터를 보내야 할때 POST 요청을 사용했다. ex) 구글 검색시 검색 메시지 전달
하지만 POST 요청에는 두가지 문제점이 있었다.
첫째, 보안에 취약
둘째, 검색 내용을 다른 사람들과 공유할 수 없음
따라서 요즘에는 URL 메소드로 데이터를 서버에 전달하는 방법을 더 많이 사용한다. GET method를 사용하며 전달할 데이터는 url에 쿼리스트링으로 추가해서 보낸다.
5. HTTP response message

일반적인 http 응답 메시지의 format이다.

status코드가 헤더 첫줄에 가장 먼저 보인다. 예시로 몇가지 상태코드와 의미가 정리되어있다.
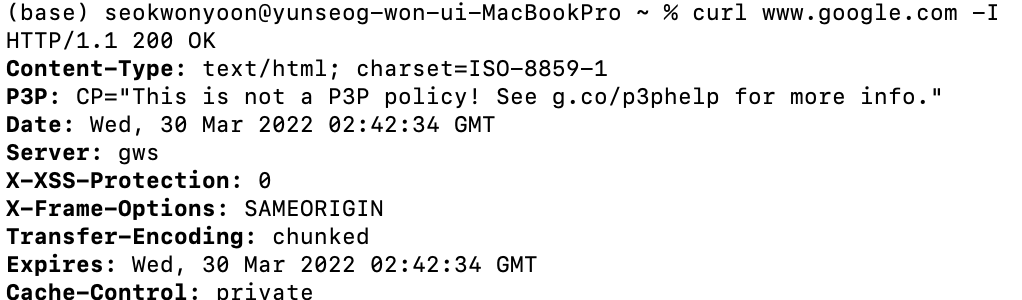
웹 브라우저에서 url을 통해 웹 페이지를 다운받는 것처럼 터미널에서도 curl 명령어로 똑같은 동작을 수행할 수 있다.
-I 옵션은 헤더만 보여준다는 뜻이다. -I를 빼면 www.google.com의 html 소스가 터미널에 출력된다.

존재하지 않는 주소로 요청을 보내고 응답 헤더만 살펴보면 404 status code가 가장 먼저 보인다.
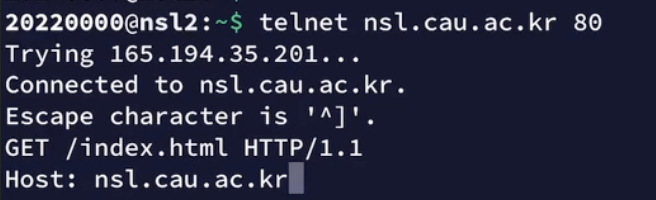
curl말고 telnet을 사용해서 원격 접속도 가능하다. 웹브라우저가 예쁘게 소스를 보여줄 뿐이지 curl, telnet등의 원격 접속과 사실상 똑같다.
GET요청을 했으니 nsl.cau.ac.kr/index.html의 소스를 다운받을 수 있다.
6. http encapsulation/decapsulation

http header/body가 payload로 담겨서 하위계층으로 전달된다.

자신의 MAC주소에 해당하면 Link frame을 수신하고 header를 떼고 payload를 상위 계층에게 올려준다.
IP datagram에서 IP header를 확인해서 dst address가 일치하면 헤더를 떼고 상위 계층으로 segment를 올려준다.
7. Cookies
http protocol 자체는 state가 없기 때문에 client, server에 대한 정보를 기억하고 있지 않는다.
하지만 우리가 웹사이트에 로그인을하면 웹사이트는 나임을 인식하고 내 정보들을 보여준다.
이게 가능한 이유는 cookie를 사용하기 때문이다.
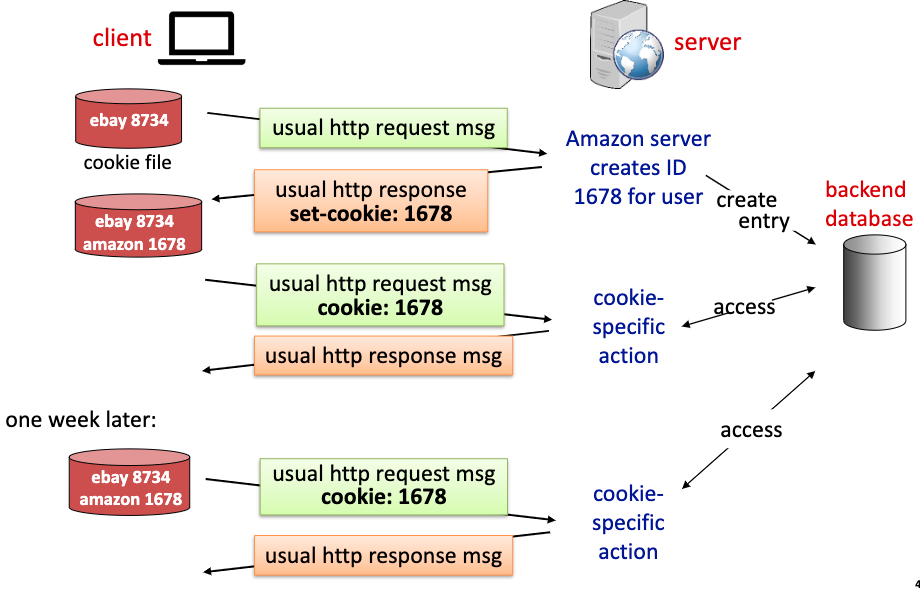
쿠키가 어떻게 state을 기억하는지 살펴보자.
1. client는 서버에게 http 요청을 보낸다.
2. 서버는 사용자에게 unique id를 부여(1678)하고 그 id를 백엔드 db에 저장한다.
3. 서버는 client에게 set-cookie : 1678 을 추가하여 응답을 보내준다.
4. 웹 브라우저는 set-cookie:1678을 확인하여 저장한다. (다음번에 amazon에 접속할때 이 정보를 사용해야지!)
5. client가 amazon에 다시 접속한다. 브라우저가 자동으로 cookie:1678를 요청에 추가해서 보낸다.
6. server는 cookie:1678을 db에서 확인하여 사용자가 누구임을 식별한다.
7. 웹브라우저와 server db가 cookie를 기억하고 있다면 일주일이 지나도 사용자 state을 기억할 수 있다.
즉 쿠키는 server가 나에 대해 더 많이 기억하고 알 수 있도록 한다.
8. Web caching (proxy server)
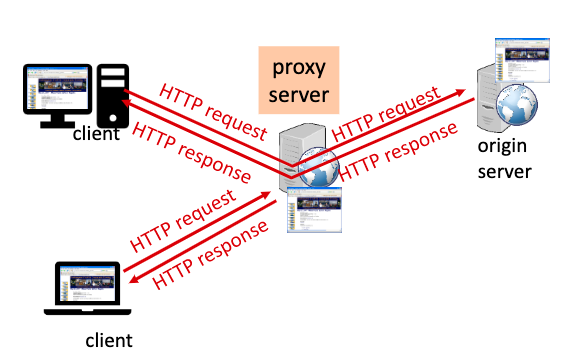
첫번째 client가 proxy서버로 http요청을 한다. proxy server는 origin server에게 http요청을 하고 응답을 받아온다. 받아온 응답을 proxy server는 cache에 저장해둔다. client에게 받은 응답을 전송해준다. (proxy서버는 client이자 server이다.)
두번째 client가 proxy 서버로 이전과 똑같은 http 요청을 한다. proxy server는 이전 응답 결과를 cache로 저장하고 있기 때문에 바로 두번째 client에게 응답을 보내준다.
이렇게 proxy server를 사용하면 origin server의 부하를 proxy server에게 나누어줄 수 있다.
web browser도 cache를 가지고 있다. 사용자가 접속하려는 웹페이지를 browser cache에서 바로 가져와서 서버 요청을 생략할 수 있다. (local cache에 없다? -> Proxy server의 cache에 없다? -> origin server로 요청)
대학, 기업, 통신사(skt, lgu, kt)같은 ISP 입장에서는 사용자들의 network usage(traffic)를 줄이기 위해 proxy,cache server를 만든다.
반면 사용자 입장에서는 더 빠른 응답을 받기 위해 cache를 사용한다.
실제로 proxy server하나를 둠으로써 얼마나 total delay가 줄어드는지 살펴보자.
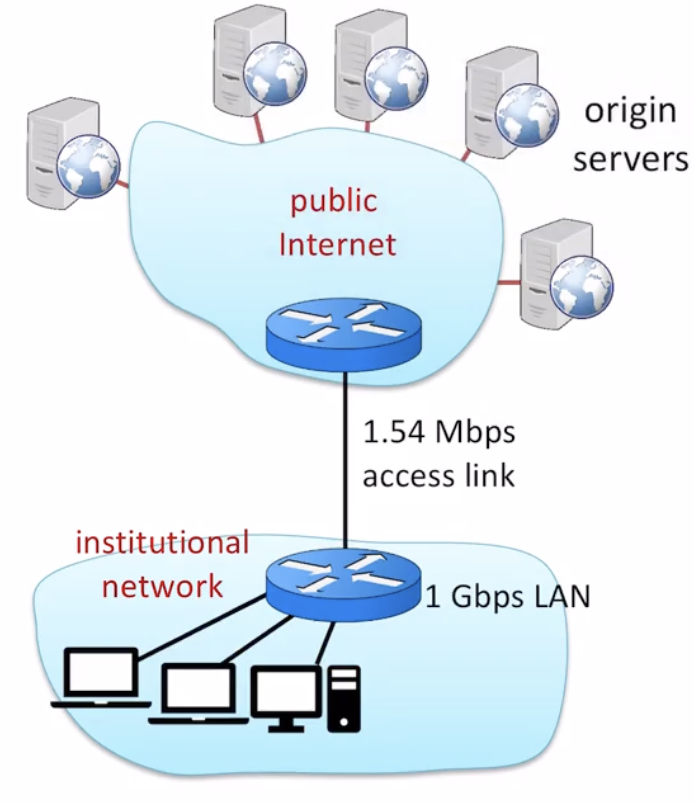
access link의 평균적인 data rate은 1.50Mbps이다.
institutional router에서 아무 origin server로의 RTT는 2sec이다.
access link의 대역폭은 1.54 Mbps이다.
acess link의 utilization은 99%(1.5/1.54)이다.
total delay = internet delay (2sec) + access delay(minute) + LAN delay(아주아주 작음)
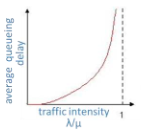
결국 total delay의 가장 큰 부분을 차지하는 요소는 access delay이다. institutional network에서 public internet으로 나가고 들어오는데 걸리는 시간을 말한다. 링크 사용률이 99퍼센트이기 때문에 평균 큐잉딜레이는 거의 minute 단위로 소요된다. (traffic intensity가 거의 1이기 때문)
물론 1.54Mbps 링크를 더 큰 대역폭의 링크로 교체하면 total delay가 2sec + a가 되지만 비용이 많이 든다.
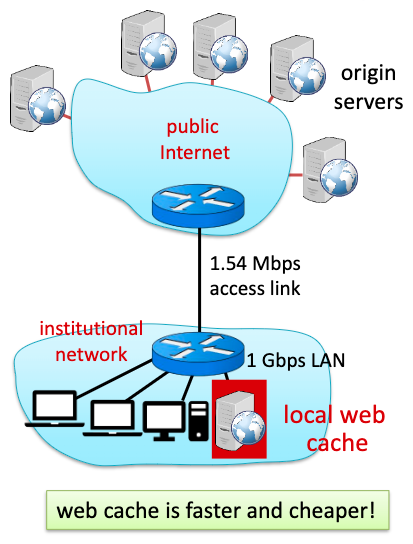
이렇게 proxy server를 하나 두었다고 하자.
cache의 hit rate은 0.4라고 가정하자. client가 원하는 결과가 proxy server에 있을 확률이 40퍼센트라는 뜻이다. 60퍼센트만 origin server로 요청하면 된다.
total delay = 0.6 * (delay from origin servers) + 0.4*(delay when satisfied at cache)
1Gbps LAN을 사용하고 있기 때문에 cache server로 부터의 delay는 상대적으로 매우 작다.
그럼 access link를 타고 나가고 들어오는 data rate은 0.6 * 1.50Mbps = 0.9 Mbps가 되고 link utilization은 0.9/1.54 = 0.58이 된다.
link utilization이 급격히 작아졌기 때문에 delay from origin servers가 2.01초라고 하면 total delay는 거의 1.2 sec가 된다.
proxy server를 두었을 때 total delay값은 access link를 훨씬 큰 대역폭의 link로 교체했을때(2sec + a) 보다 작다.
Conditional GET
proxy server가 cache에 보관하고 있는 내용이 origin server에서 최근에 업데이트 되어 proxy server, origin server가 서로 다른 내용을 가지고 있을 수 있다.
이런 불일치 여부를 확인하기 위해 cache server가 origin server에게 conditional get을 사용할 수 있다.
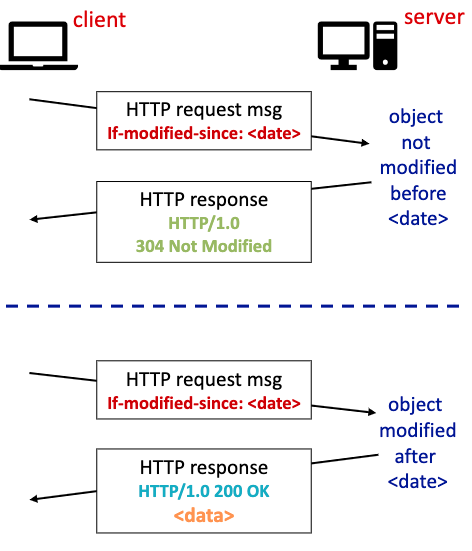
cache서버가 origin server에게 conditional get 요청을 보낸다.
if-modified-since:<date> 내용을 첨부해서 <data>전에 수정된 내용이 있는지 확인해달라고 요청한다. 수정된 내용이 없다면 origin server는 304 not modified 응답을 보내준다.
만약 <date>이후로 수정된 내용이 있다면 요청한 데이터를 다시 보내준다 (status:200)
'ComputerScience > Network' 카테고리의 다른 글
| Transport Layer - 1. Introduction (0) | 2022.03.30 |
|---|---|
| Application Layer - 4. e-mail, DNS, video streaming (0) | 2022.03.30 |
| Socket programming (Golang) (0) | 2022.03.22 |
| Socket programming (Python) (0) | 2022.03.21 |
| Application Layer - 2. transport layer service, TCP/UDP (0) | 2022.03.21 |



