1. Deep Learning
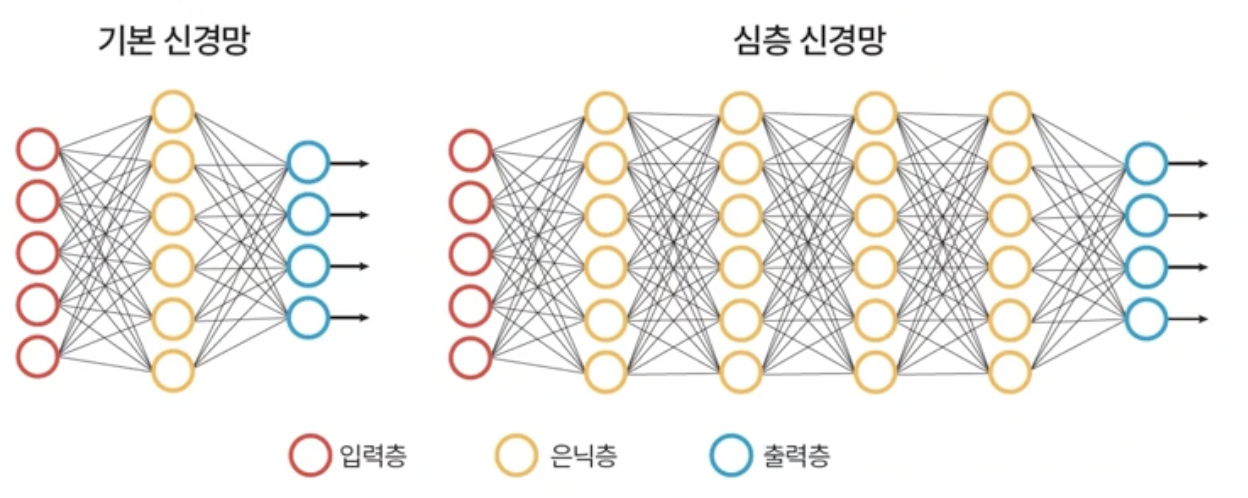
- DNN, 다층 퍼셉트론에서 은닉층의 수를 증가시킨 것.
- 컴퓨터 시각, 음성 인식, 자연어 처리에 많이 응용되고 있다.
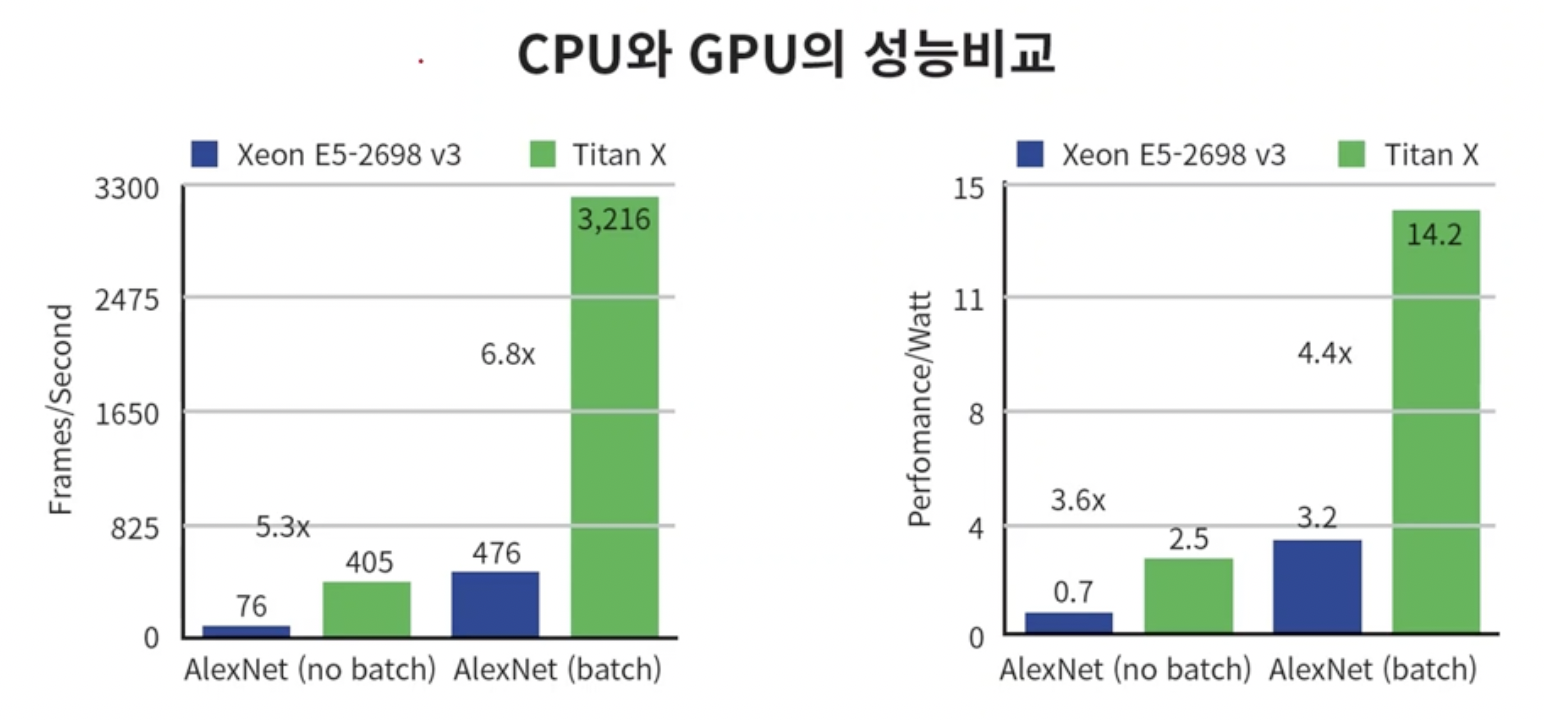
- 딥러닝을 활용할 수 있었던 가장 큰 이유중 하나는 gpu(graphic processor unit)기술이다.
- DNN의 학습시간은 상당히 느리고 학습과정이 계산 집약적이다. gpu의 등장으로 훨씬 빠른 시간에 학습을 마칠 수 있게 되었다.
- 입력층으로 input이 들어오면 각 층에서 feature를 추출한다.
- 고전적인 얼굴 인식 방법은 사진에서 edge, corner등을 탐색하는 알고리즘을 짰지만 Deep learning network는 알아서 각 은닉층들이 필요한 feature들을 추출한다.
- muli layer perceptron은 사람이 직접 판단을 위한 특징을 추출하여 input으로 모델에 넣어주어 그 데이터들을 분류하는 fitting함수를 찾았었다.
- 하지만 심층신경망은 알아서 학습하여 특징을 추출한다.


2. Vanishing gradient
- 심층신경망이 알아서 특징을 추출하여 분류를 해주지만 우리가 의도하지 않은 방향으로 결과가 흘러갈 위험이 있다.
- 그 중 하나가 그라디언트 소실이다.
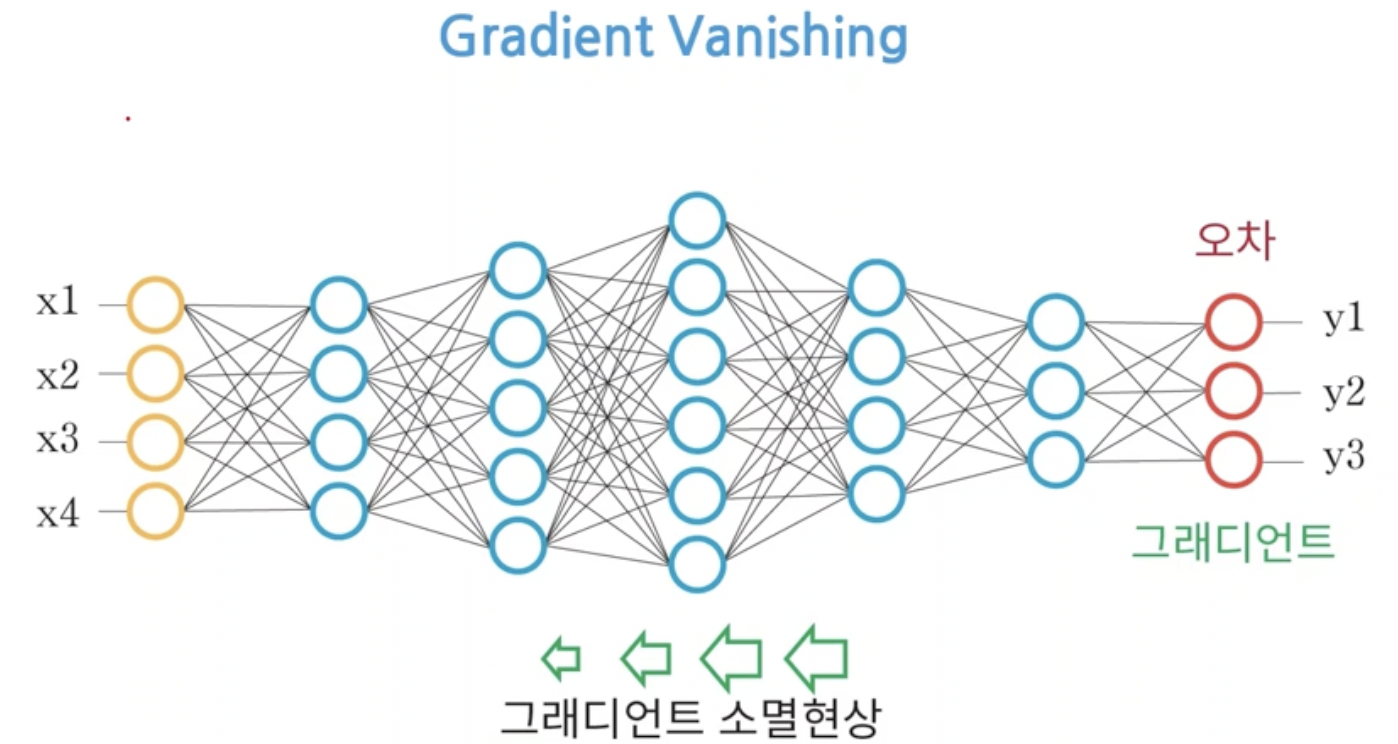
- DNN에서도 출력층으로부터 back propagation이 수행된다.
- 한 층씩 뒤로 돌아가면서 gradient를 계산하여 가중치의 업데이트가 진행되어야 하는데 그라디언트가 0이되는 현상이 생길 수 있다.
- 즉 결과의 오차는 존재하는데 가중치의 update가 안되는 현상이 발생한 것이다. 이렇게 되면 올바른 학습이 불가능하다.
- 꼭 그라디언트가 0이 아니더라도 0.0001처럼 매우 작은 값이 될 수 있다.
- 이런 경우에는 최적화 지점까지 도달하기 위해 학습에 엄청난 시간이 걸릴 수 있다.
- 이런 현상을 발생시키는 원인은 sigmoid 함수에 있다.
- 활성함수의 아주 큰 양수나 아주 큰 음수가 들어오면 gradient가 0이 되어버린다.
- 이 때문에 vanishing gradient가 발생한다.
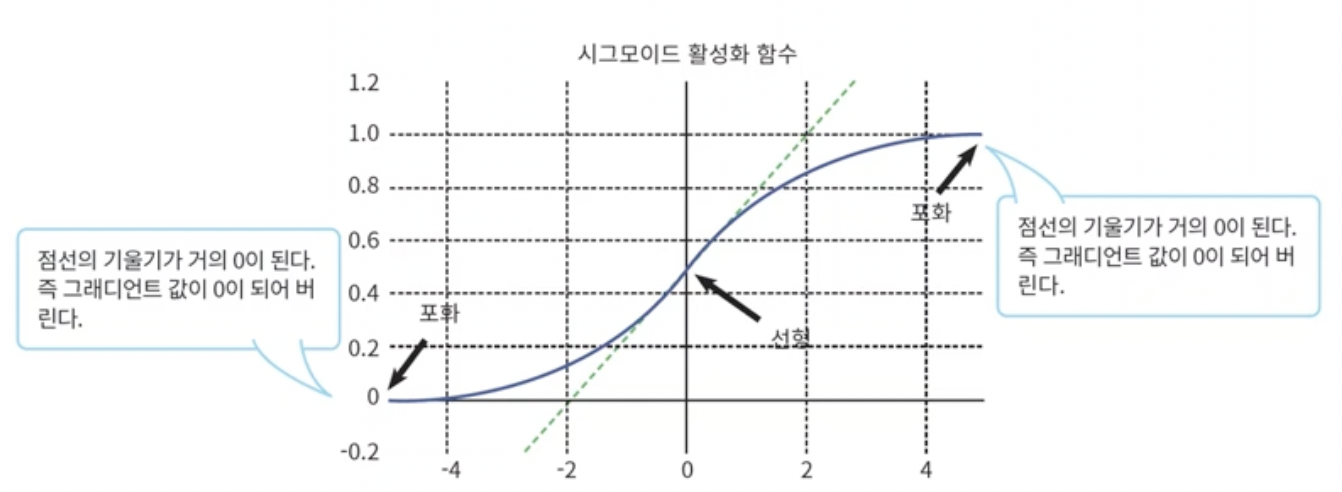
- 즉 활성화 함수의 값이 0 이 되어버려 chain rule에 의해 구한 gradient가 0이 되는 것이다.
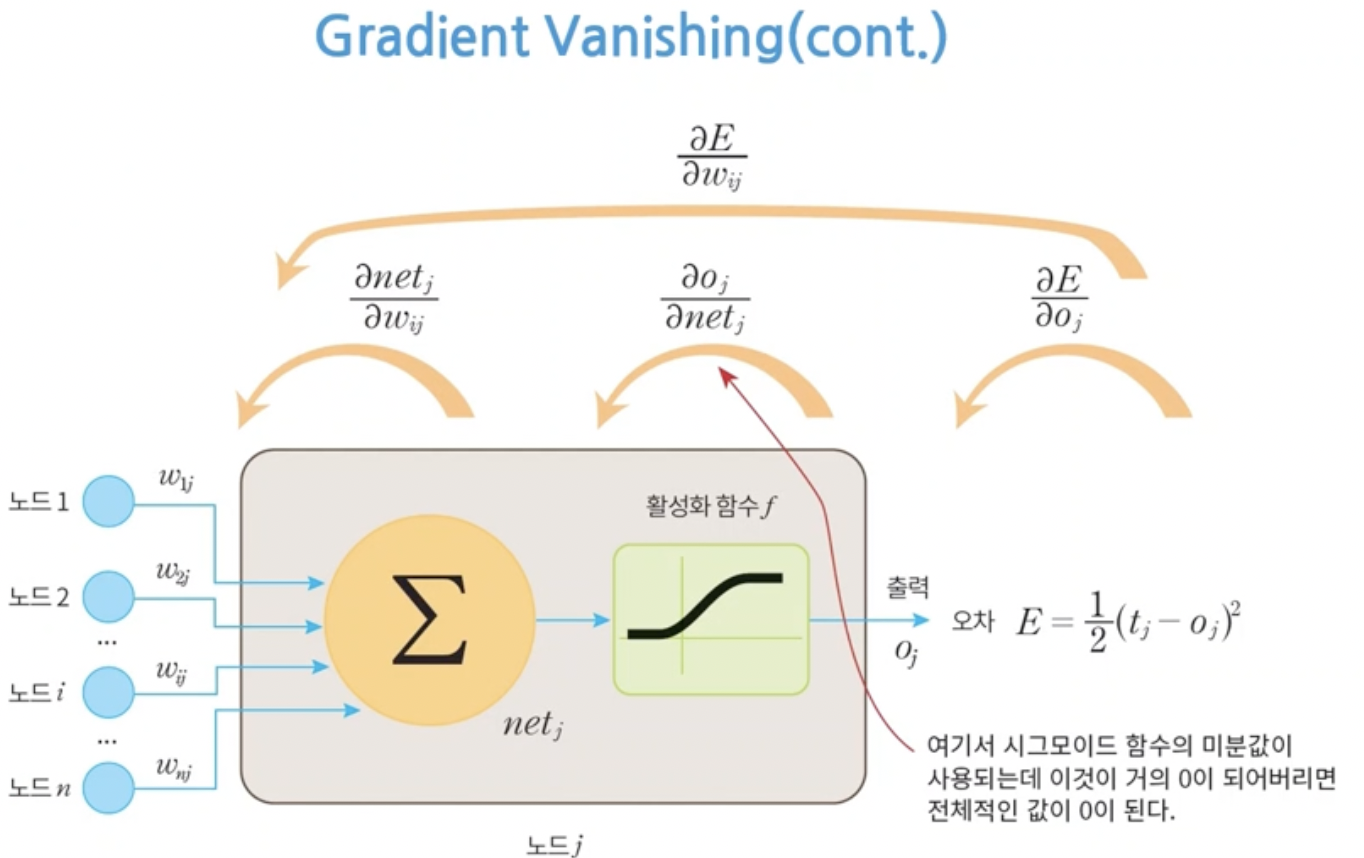
- 그래서 새로운 활성화 함수를 찾게 되었다. 그 예시중 하나가 ReLU이다.

3. Problem of Loss function
- 일반적으로 MSE(mean squared error)를 많이 사용한다.

- sigmoid를 썼을 때 만약 오차가 0.001처럼 아주 작게 되면 제곱을하여 gradient를 구하기 때문에 gradient가 더 작은 값이 되어버린다. slow convergence(저속수렴)문제가 다시 발생한다.
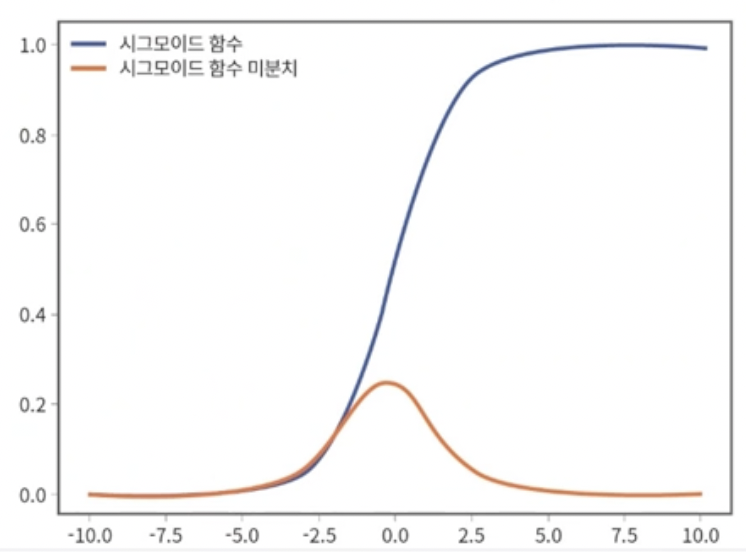
- input값이 매우 크거나 작아지면 sigmoid함수의 미분치는 거의 0이 된다.
- 우리가 원하는 목표값이 0이고 실제 출력값이 10이면 오차는 매우크지만 그라디언트는 0이 되어버린다. 즉 오차가 있는데도 가중치를 업데이트할 수 없다.
- 그래서 대안으로 찾은 것이 활성화 함수로는 softmax를 사용하고 loss함수로는 cross entropy를 많이 사용한다.
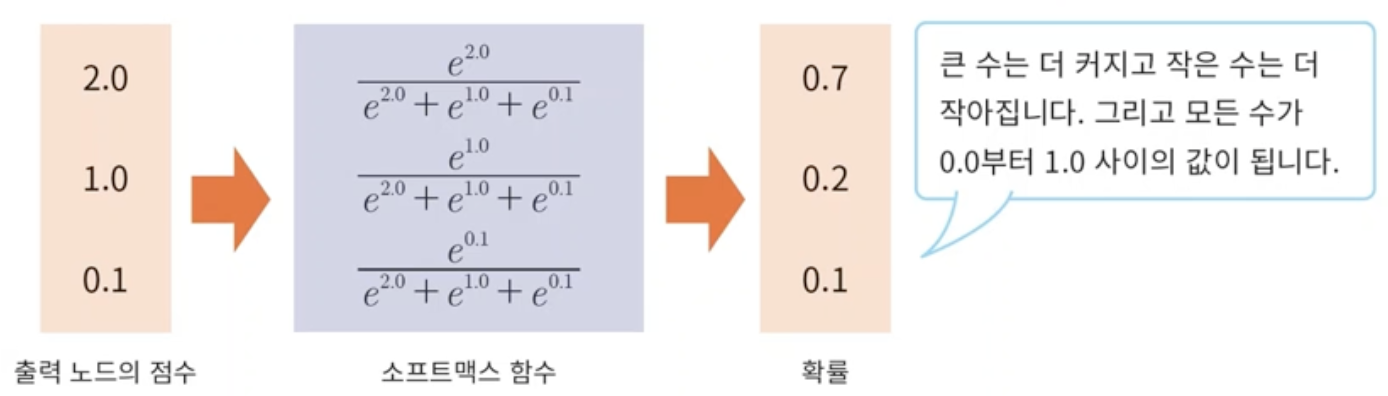
- mse가 단순히 둘간의 거리를 비교했다면 cross entropy는 두개의 확률분포간의 거리를 비교한다.
- 두개의 확률분포 p,q에 대해서 loss는 아래 식으로 구한다.
- cross entropy가 크면 두 분포는 많이 다른것이고 반대로 값이 작으면 두 분포는 거의 일치한다 볼 수 있다.
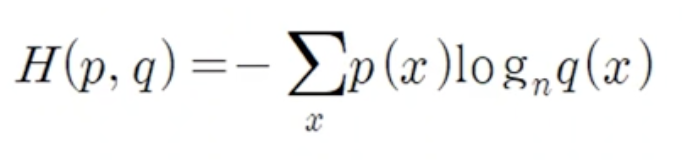
- 실제 출력과 label의 교차 엔트로피 loss값을 구하는 과정은 아래에 있다.

4. Problem in Weight initialization
- 출력층에서 계산된 오차는 가중치 값에 비례하여 역전파된다. (가중치가 곱해져서 역전파됨)
- 따라서 만약 가중치가 0이라면 back propagation이 제대로 이루어지지 않을 수 있다.
- 따라서 weight들을 초기화하는 일은 매우 중요하다.
- 그 대안으로 xavier가 고안한 방법이 있다. 아래 같은 분산을 가지는 정규분포에서 난수를 추출하여 초기화하는 방법이다.
- Nin 대신 Nout으로도 할 수 있다.

- 아예 0 아닌 다른 하나의 값으로 초기화하면 되지 않을까? 할 수 있지만 각 노드의 weight들이 back propagation중에 전부 같은 값으로 update될 위험이 있다. 즉 특정 feature마다 중요하고 덜 중요하고를 따지지 않게 된다.
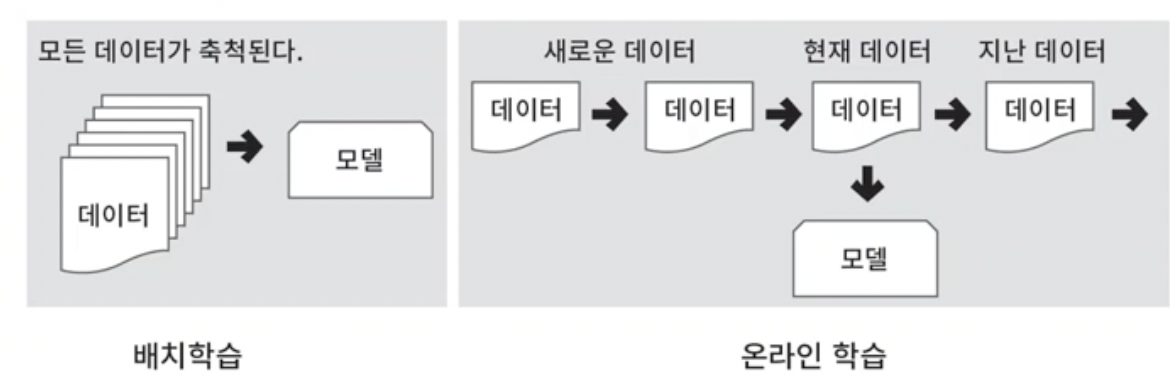
5. Minibatch
- Stochastic gradient descent는 하나의 샘플이 주어질 때마다 바로 오차를 구하여 가중치를 업데이트 한다. online learning이라고도 한다.
- batch learning은 batch의 모든 샘플을 보고나서 각 샘플의 gradient를 모두 더해 가중치 변경에 사용한다.
- 배치학습은 batch에 있는 데이터들의 유사성을 학습하는데 더 유리할 수 있다. 노이즈에 덜 취약하지만 데이터가 많을수록 처리에 많은 시간이 소요된다. 왜냐하면 여러개의 샘플을 보고 한번에 가중치를 업데이트하기 때문이다.
- 즉 서로 장단점이 있는 방법이고 그라디언트를 업데이트하는 방식에서 차이가 있다.
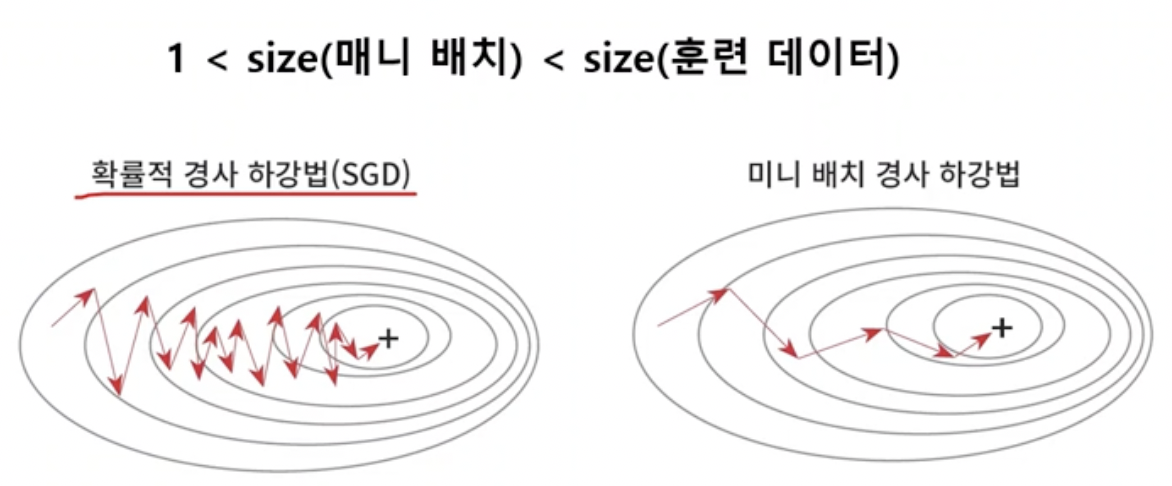
- 속도도 적당히 빠르고 잡음에도 덜 취약한 방법으로 mini batch가 등장했다.
- 전부다 보거나 하나만 보지말고 적당한 크기의 배치를 보고 업데이트를 수행하는 것이다. 즉 train set을 작은 부분집합들로 나누는 것이다.
- sgd에 비해 미니배치는 평균적으로 안정적인 Point들을 거쳐 도달하게 된다.
6. Data normalization
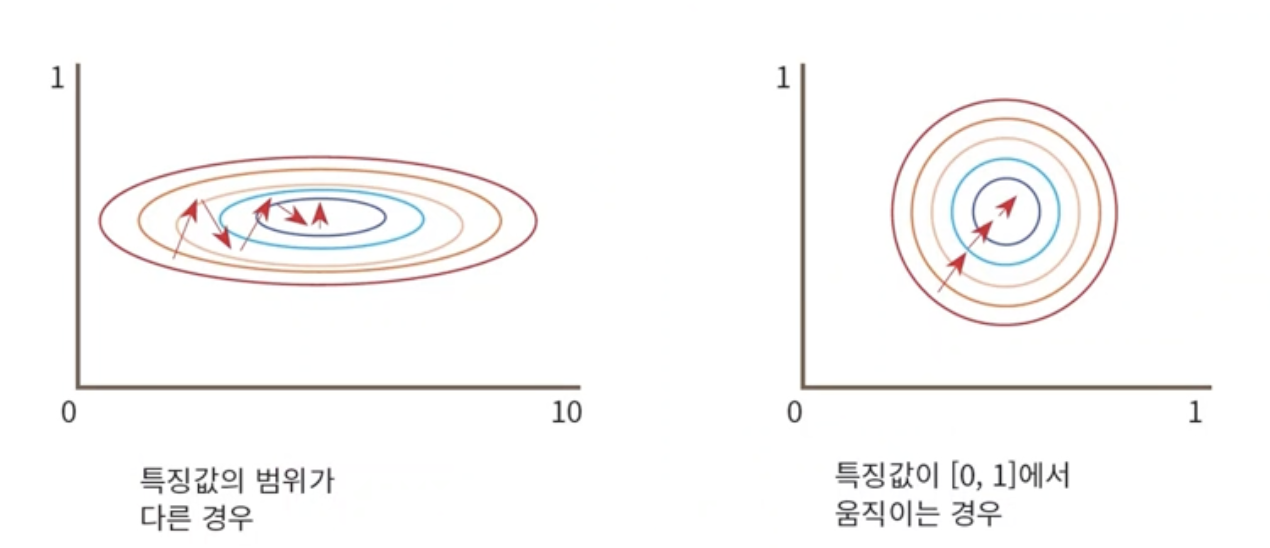
- 입력으로 들어오는 데이터의 범위가 다른 왼쪽의 경우를 살펴보자.
- y축 특징의 오차는 커봤자 1인데 x축 특징의 오차는 10까지도 가능하다. 즉 역전파시에 weight를 업데이트할때 gradient가 급격하게 커질 수 있다.
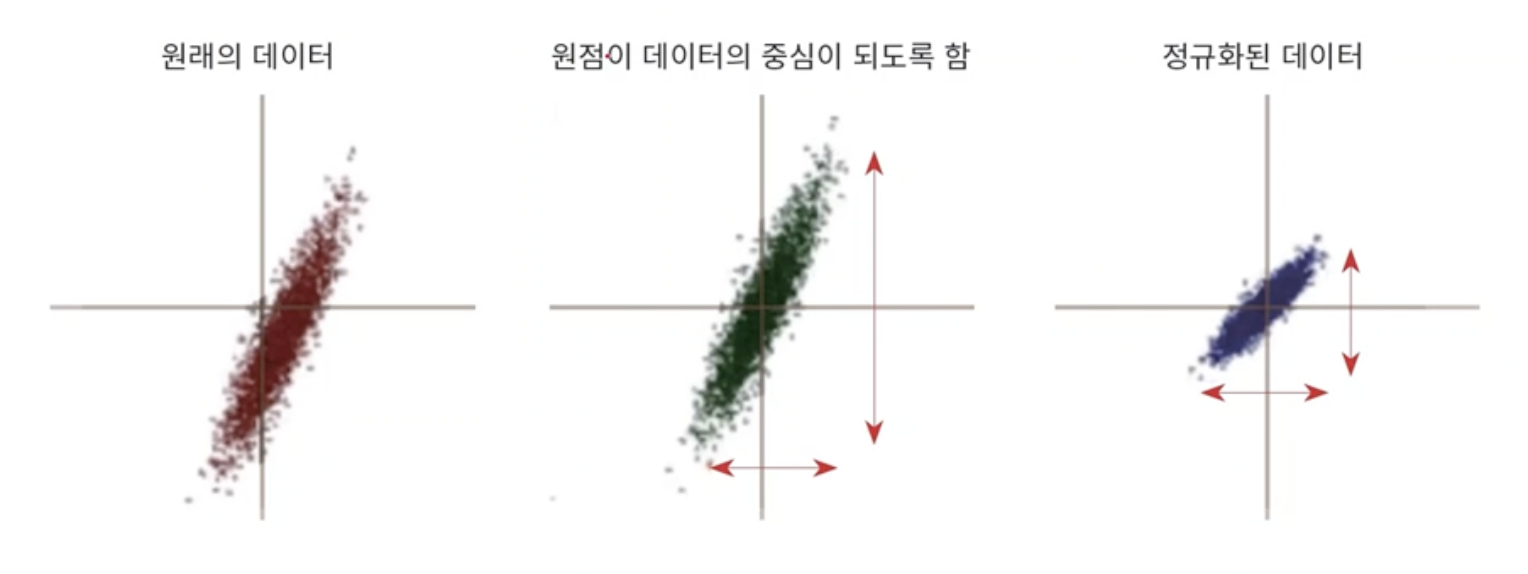
- 따라서 데이터의 물리적 크기가 학습에 영향을 미치지 않도록 하기 위해 오른쪽 처럼 0,1 사이로 균일하게 normalization(정규화)을 수행한다.
- 이렇게 하면 편차가 큰 값을 gradient를 구해서 더 많이 바꾸는 작업을 피해서 안정적인 학습이 이루어지게 된다.
7. Data Encoding
- 나이 성별 급여 선호차에 대한 정보를 바로 넣을 수 없으니 수치화된 값으로 매칭하여 input으로 전달한다.

- y = xw + b에서 x에 suv를 넣을수 없으니 수치로 변환한다.
- 정리하면 데이터 인코딩은 우리가 가지고 있는 정보를 네트워크가 학습할 수 있도록 변환하는 방법이다.
8. Learning rate
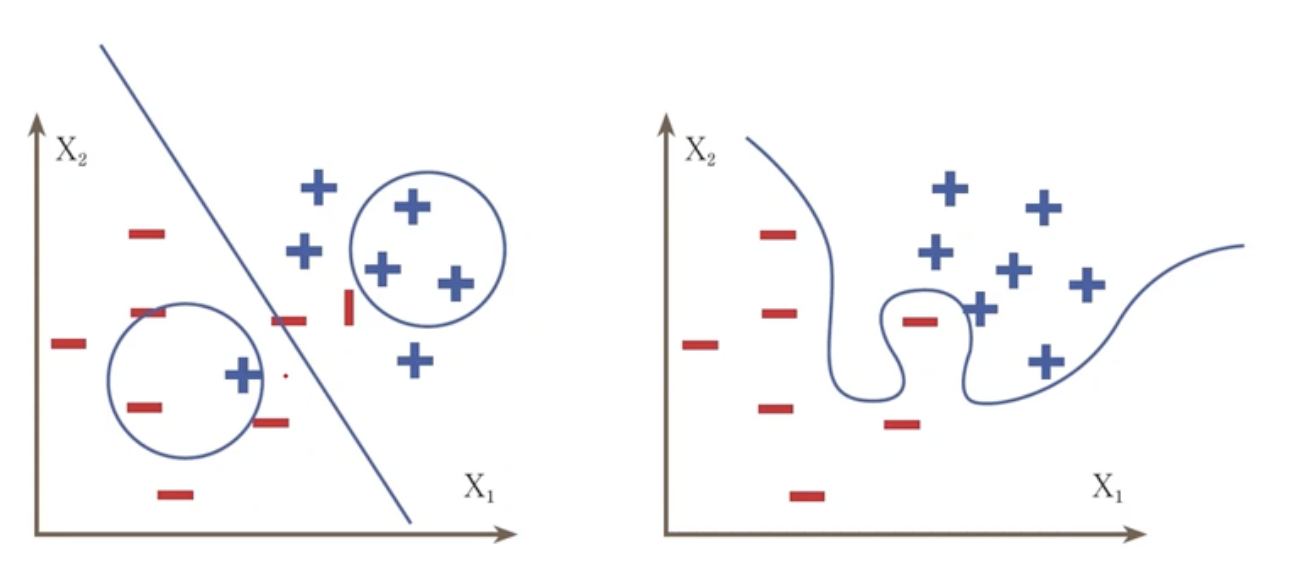
- 이제까지는 학습을 방해하는 요인들을 살펴보았다. 이제부터는 학습이 과잉적합 되는 상황들을 막을 수 있는 방법들을 살펴보자.
- gradient로 weight를 업데이트하는 비율이 learning rate이다. 너무 낮으면 학습이 느리고 너무 크면 발산한다.

- 그라디언트의 반영비율이 너무 크면 밑으로 내려가는 크기가 너무 커져서 오히려 함수에서 이상한 위치에 도달한다. 이를 발산한다고 한다.
9. Momentum
- 학습을 가속시킬 목적으로 사용한다.
- local minima에 빠지는 것을 막아준다.

- 그림에서 보면 global minima에 도달하기 전에 local minima를 빠져나오고 있다.
- 수식을 보면 learning rate는 거의 고정된 값을 사용하기 때문에 gradient가 작아지면 weight의 업데이트가 느려진다.
- 따라서 학습을 빠르게 하기 위해 momentum*w(t)를 한 값을 더해준다.
- 따라서 local minima에 빠지더라도 momentum을 더해줘서 벗어날 수 있게 된다.
- 따라서 momentum을 줌으로써 overfitting(local minima에 빠짐)을 방지할 수 있다.

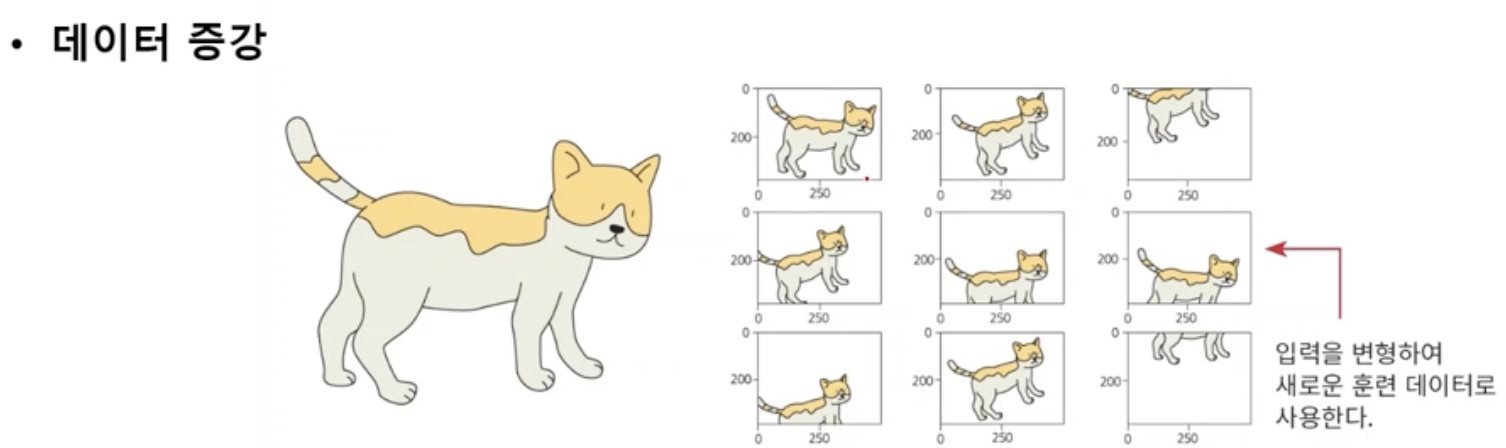
10. Data augmentation
- 학습데이터가 적어서 생기는 overfitting, underfitting을 보완하기 위해 데이터를 변형하여 학습데이터를 증가시킨다.
- scale, 상하좌우 반전 등을 활용한다.
11. Dropout
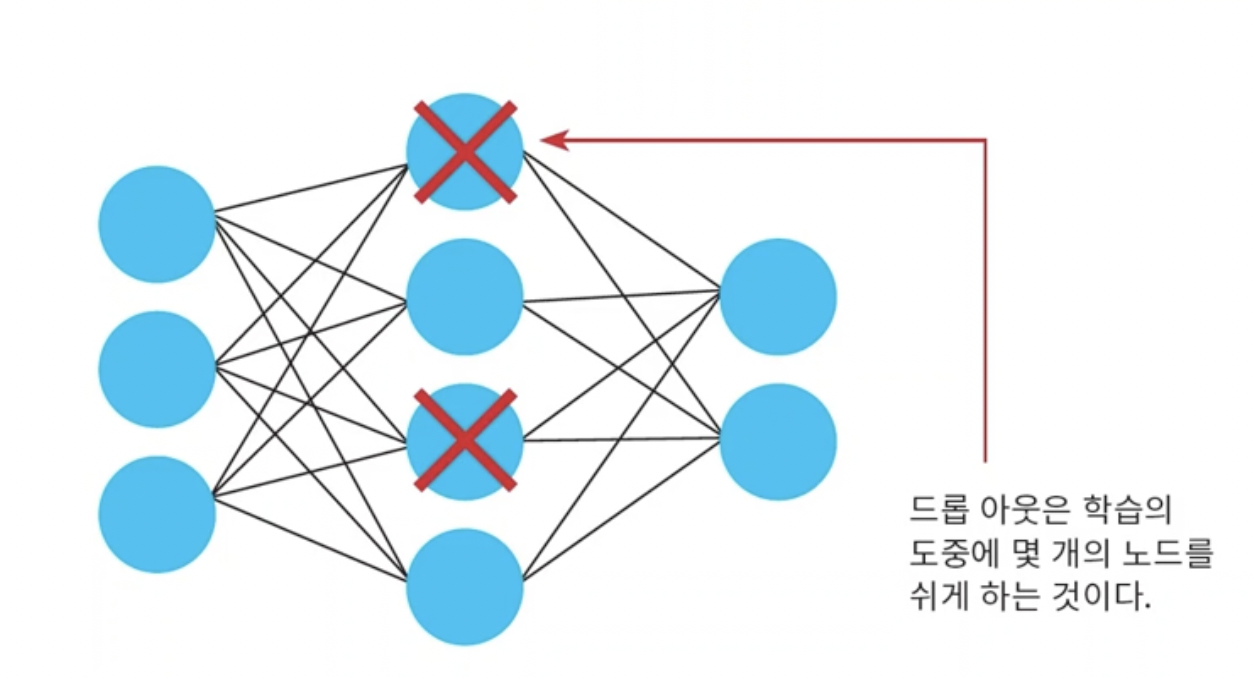
- depth가 점점 깊어지고 하면 노드들에서 overfitting이 발생할 수 있다.
- 노드들이 너무 detail한 많은 요소까지 학습해버리면 overfitting이 발생하니까 이를 방지하기 위해 dropout을 활용한다.
- 강제로 몇개의 노드를 쉬도록하여 과적합을 막는다.
- 아래 그래프를 보면 Loss가 너무 떨어지는 것을 막는다.

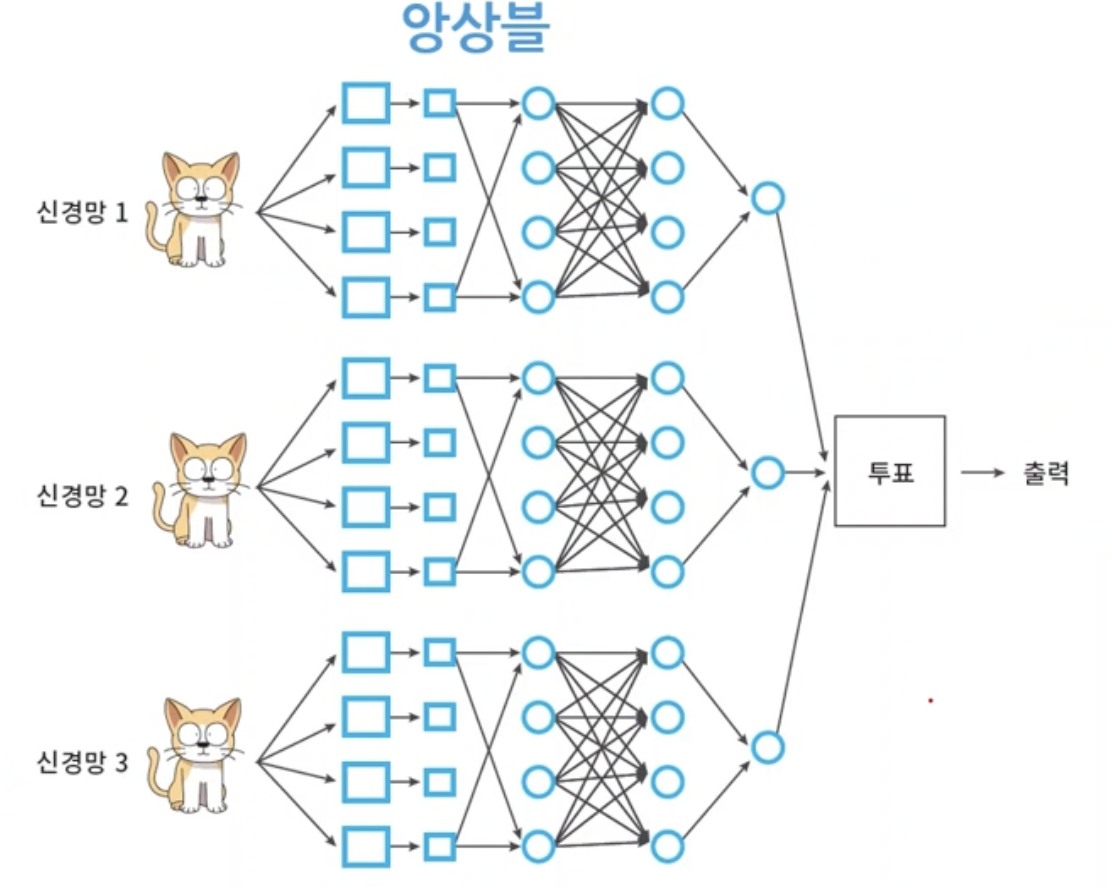
12. Ensemble
- A, B, C 세개의 모델이 있다고 하자. 각각의 고양이 인식률을 87, 86, 80이다.
- A는 작은 고양이는 특별히 잘 찾아낸다. B는 가려진 고양이를 잘 찾아내고 C는 큰 고양이사진을 잘 판별한다.
- 세 모델이 각각 모든 고양이 인식을 커버하면 정확도가 80대 밖에 안되지만 각각 잘하는 것만 하면 인식률이 더 높아질 수 있다.
- 따라서 세 모델이 예측한 결과를 투표하여 하나의 출력으로 선택하는 것을 앙상블이라고 한다.
- 즉 따로따로 학습을 시킨 여러 신경망을 나중에 voting algorithm으로 하나로 모은 것이다.
- 기존의 신경망을 여러개 활용하는 장점 말고도 앙상블로 나온 더 나은 결과를 가지고 새로운 모델을 학습하는 것도 가능하다.
'ComputerScience > Machine Learning' 카테고리의 다른 글
| Deep Learning - 1.1 Data manipulation (0) | 2022.07.27 |
|---|---|
| AI - 13. Convolutional Neural Network (0) | 2021.12.10 |
| AI - 11. Multilayer Perceptron (0) | 2021.11.25 |
| AI - 10. Perceptron (0) | 2021.11.18 |
| AI - 9. kNN, Gaussian Mixture (0) | 2021.11.11 |



