Dropout and Batch Normalization
Explore and run machine learning code with Kaggle Notebooks | Using data from DL Course Data
www.kaggle.com
*Kaggle에서 제공하는 Deep Learning Tutorial을 학습하며 번역한 내용입니다.
Introduction
deep learning은 dense layers만으로 구성되는 것은 아니다. model에 더할 수 있는 수십가지 종류의 layers가 있다.
이제까지는 dense layers와 neurons간의 connections를 정의하였다. 다른 layer의 경우, preprocessing 혹은 다른 종류의 transformations을 할 수 있다.
이번 장에서는 두 종류의 특별한 layer에 대해 공부한다. 이 layer들은 neurons으로 구성되지 않기 때문에 몇가지 기능을 추가해서 model에게 강점을 부여한다. 이 두가지 layers는 modern architectures에서 자주 쓰인다.
Dropout
처음 소개할 layer는 dropout layer이다. overfitting을 correct하는데 유용하다.
데이터를 학습시킬 때 가짜 패턴을 network가 익힘으로써 발생되는 overfitting에 대해서 공부했었다.
이 가짜 패턴을 network가 인식하기 위해서는 weights의 조합에 의존해야 할 때가 있다.
conspiracies를 부수기 위해 매 training step마다 무작위로 layer's input units중 일부를 drop out시킨다. network가 가짜 패턴을 학습하는 것을 더 어렵게 하는 것이다. 대신 더 넓게 탐색해서 general한 패턴을 찾아 weight 패턴을 더 튼튼하게 한다.
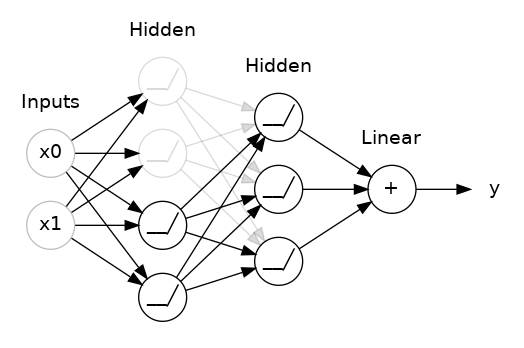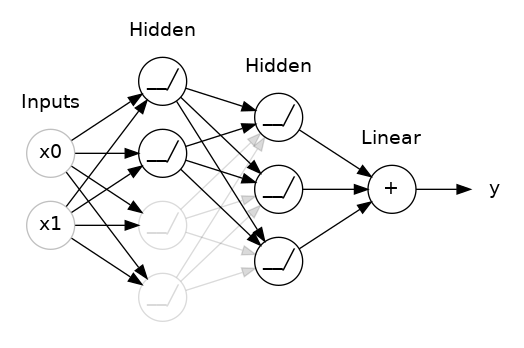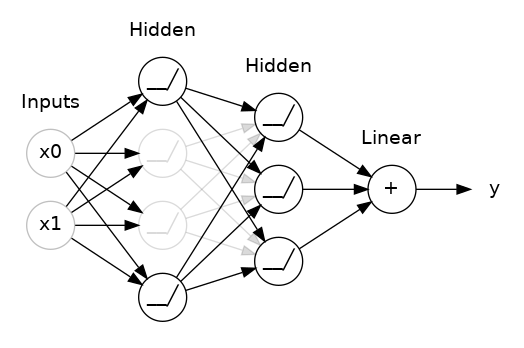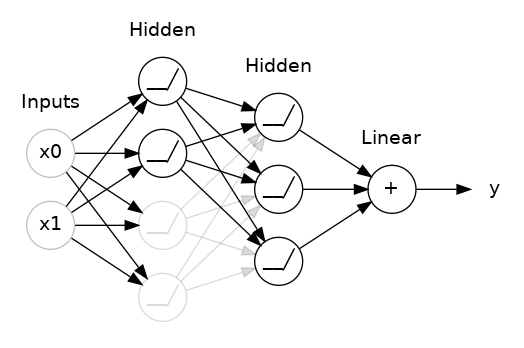
두 hidden layers사이에 50% dropout을 추가한 모습이다. dropout을 networks의 앙상블 중 하나를 만드는 것으로 생각해도 된다. 하나의 큰 network에 의한 예측은 더 이상 불가능하지만 smaller networks의 연합이 이를 대신할 것이다. 전체 committee의 individuals는 서로 다른 종류의 mistakes를 만드는 경향이 있지만 commitee를 이룸으로써 더 나은 결과를 만들 것이다. (random forests, ensemble of decision tree와 같은 idea이다)
Adding Dropout
케라스에서 dropout 인자로 input unit의 몇 퍼센트를 shut off할지 정할 수 있다.
keras.Sequential([
# ...
layers.Dropout(rate=0.3), # apply 30% dropout to the next layer
layers.Dense(16),
# ...
])Batch Normalization
두번째로 소개할 layer는 batch normalization이다. slow하거나 unstable한 training의 교정에 유용하다.
공통된 scale로 데이터를 neural networks에 넣는 것은 일반적으로 좋은 생각이다. 그 이유는 SGD가 network weights를 data가 만드는 activation이 얼마나 크냐에 따라 변화시키기 대문이다.
서로 다른 크기의 activation을 만들어내는 features가 unstable한 training을 만들 수 있다.
network로 데이터가 진입하기 전에 normalize하는게 좋다면 network안에서 normalizing하는 것은 더 좋을 것이다.
실제로 이 역할을 수행하는 layer가 있는데 이를 batch normalization layer라고 한다.
batch normalization layer는 자신에게 들어오는 batch를 먼저 살펴본다. 가장 먼저 자기가 갖고 있는 mean, standard deviation을 가지고 normalize한다. 그 다음으로 두 trainable rescaling parameters로 data를 새로운 scale에 둔다.
Batchnorm은 inputs에 대해 일종의 rescale된 좌표계의 역할을 수행한다.
종종 batchnorm은 구급상자 처럼 optimzation process에 추가되기도 한다.
batchnorm이 있는 model은 training을 마치기 위해 적은 epochs를 필요로하는 경향이 있다. 더욱이 batchnorm은 학습이 막히게 하는 다양한 문제들을 고칠 수 있도록 해준다.
만약 학습 과정에서 막히는게 있다면 batch normalizaion을 model에 추가하는 것을 고려해 볼 수 있다.
Adding Batch Normalization
batch normalizaion은 network의 아무 지점에 넣어도 된다.
layers.Dense(16, activation='relu'),
layers.BatchNormalization(),layer뒤에 넣어도 되고 아래 코드 처럼 사이에 넣어도 된다.
layers.Dense(16),
layers.BatchNormalization(),
layers.Activation('relu'),만약 network의 첫 layer에 추가한다면 일종의 adaptive preprocessor로 작동할 수 있다.
Example - Using Dropout and Batch Normalization
Red wine model을 완성해보자. capacity를 더 키우고 dropout을 추가(to control overfitting)하자. 그리고 batch normalization을 추가해서 optimizaion을 가속화 해보자. batch normalizaion이 어떻게 training을 안정적으로 만드는지 살펴보자.
아래 코드는 준비를 내용이다.
# Setup plotting
import matplotlib.pyplot as plt
plt.style.use('seaborn-whitegrid')
# Set Matplotlib defaults
plt.rc('figure', autolayout=True)
plt.rc('axes', labelweight='bold', labelsize='large',
titleweight='bold', titlesize=18, titlepad=10)
import pandas as pd
red_wine = pd.read_csv('../input/dl-course-data/red-wine.csv')
# Create training and validation splits
df_train = red_wine.sample(frac=0.7, random_state=0)
df_valid = red_wine.drop(df_train.index)
# Split features and target
X_train = df_train.drop('quality', axis=1)
X_valid = df_valid.drop('quality', axis=1)
y_train = df_train['quality']
y_valid = df_valid['quality']dropout을 더하기 위해서는 Dense layers의 units 수를 증가시킬 필요가 있다.
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(1024, activation='relu', input_shape=[11]),
layers.Dropout(0.3),
layers.BatchNormalization(),
layers.Dense(1024, activation='relu'),
layers.Dropout(0.3),
layers.BatchNormalization(),
layers.Dense(1024, activation='relu'),
layers.Dropout(0.3),
layers.BatchNormalization(),
layers.Dense(1),
])model.compile(
optimizer='adam',
loss='mae',
)
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=256,
epochs=100,
verbose=0,
)
# Show the learning curves
history_df = pd.DataFrame(history.history)
history_df.loc[:, ['loss', 'val_loss']].plot();
data를 바로 학습에 사용하기 전에 standardize를 하면 훨씬 더 좋은 성능을 보이는 것을 확인할 수 있다.
Exercise
이번 연습에서는 Spotify model에 dropout을 더할 것이다. 또한 어려운 dataset에서 model이 batch normalization으로 어떻게 성공적으로 학습하는지 살펴볼 것이다.
# Setup plotting
import matplotlib.pyplot as plt
plt.style.use('seaborn-whitegrid')
# Set Matplotlib defaults
plt.rc('figure', autolayout=True)
plt.rc('axes', labelweight='bold', labelsize='large',
titleweight='bold', titlesize=18, titlepad=10)
plt.rc('animation', html='html5')
# Setup feedback system
from learntools.core import binder
binder.bind(globals())
from learntools.deep_learning_intro.ex5 import *일단 Spotify dataset을 load하자.
import pandas as pd
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import make_column_transformer
from sklearn.model_selection import GroupShuffleSplit
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras import callbacks
spotify = pd.read_csv('../input/dl-course-data/spotify.csv')
X = spotify.copy().dropna()
y = X.pop('track_popularity')
artists = X['track_artist']
features_num = ['danceability', 'energy', 'key', 'loudness', 'mode',
'speechiness', 'acousticness', 'instrumentalness',
'liveness', 'valence', 'tempo', 'duration_ms']
features_cat = ['playlist_genre']
preprocessor = make_column_transformer(
(StandardScaler(), features_num),
(OneHotEncoder(), features_cat),
)
def group_split(X, y, group, train_size=0.75):
splitter = GroupShuffleSplit(train_size=train_size)
train, test = next(splitter.split(X, y, groups=group))
return (X.iloc[train], X.iloc[test], y.iloc[train], y.iloc[test])
X_train, X_valid, y_train, y_valid = group_split(X, y, artists)
X_train = preprocessor.fit_transform(X_train)
X_valid = preprocessor.transform(X_valid)
y_train = y_train / 100
y_valid = y_valid / 100
input_shape = [X_train.shape[1]]
print("Input shape: {}".format(input_shape))두개의 dropout layers를 추가하는데 하나는 128 units의 Dense layer뒤에 다른 하나는 64 units Dense layer뒤에 추가하자. dropout rate 는 둘다 0.3이다.
# YOUR CODE HERE: Add two 30% dropout layers, one after 128 and one after 64
model = keras.Sequential([
layers.Dense(128, activation='relu', input_shape=input_shape),
layers.Dropout(0.3),
layers.Dense(64, activation='relu'),
layers.Dropout(0.3),
layers.Dense(1)
])drop out을 추가한 효과를 살펴보기 위해 학습을 진행해보자.
model.compile(
optimizer='adam',
loss='mae',
)
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=512,
epochs=50,
verbose=0,
)
history_df = pd.DataFrame(history.history)
history_df.loc[:, ['loss', 'val_loss']].plot()
print("Minimum Validation Loss: {:0.4f}".format(history_df['val_loss'].min()))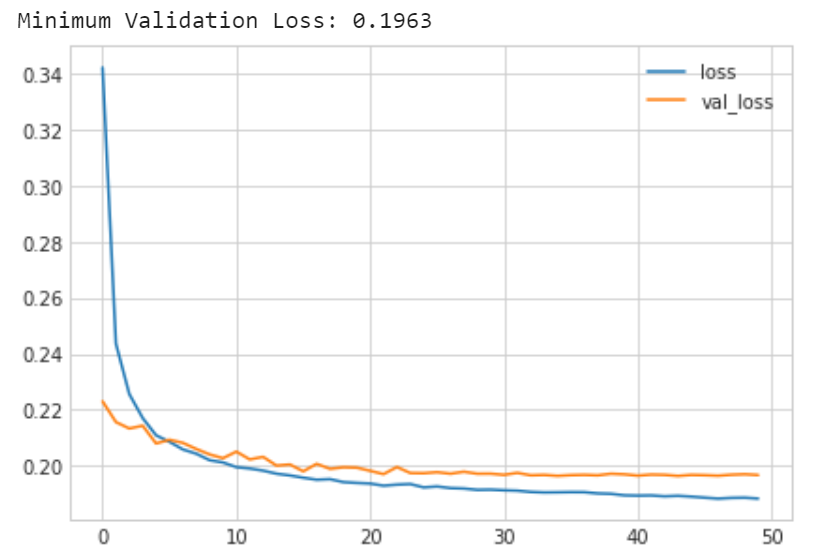
저번 exercise에서는 위의 model이 overfit을 보이는 경향이 있었는데 지금은 overfit을 잘 피한 것 같다.
learning curves를 보면 training loss가 계속 줄고있는 동시에 validation loss는 일정한 최소값으로 수렴하고 있는것 볼 수 있다. 즉 dropout이 overfitting을 막고 있음을 알 수 있다. 게다가 network가 가짜 패턴을 fit하는 것을 어렵게 함으로써 ture pattern을 network가 찾도록 해주었다.
이번에는 주제를 바꿔서 batch normalizaion으로 training에서의 문제를 해결해 보자. Concrete dataset을 load하는데 이번에는 standardizaion을 하지 않을 것이다. batch normalizaion의 효과를 더 명확하게 하기 위해서 이다.
import pandas as pd
concrete = pd.read_csv('../input/dl-course-data/concrete.csv')
df = concrete.copy()
df_train = df.sample(frac=0.7, random_state=0)
df_valid = df.drop(df_train.index)
X_train = df_train.drop('CompressiveStrength', axis=1)
X_valid = df_valid.drop('CompressiveStrength', axis=1)
y_train = df_train['CompressiveStrength']
y_valid = df_valid['CompressiveStrength']
input_shape = [X_train.shape[1]]unstandardized Concrete data를 바로 network에게 학습시켜보자.
model = keras.Sequential([
layers.Dense(512, activation='relu', input_shape=input_shape),
layers.Dense(512, activation='relu'),
layers.Dense(512, activation='relu'),
layers.Dense(1),
])
model.compile(
optimizer='sgd', # SGD is more sensitive to differences of scale
loss='mae',
metrics=['mae'],
)
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=64,
epochs=100,
verbose=0,
)
history_df = pd.DataFrame(history.history)
history_df.loc[0:, ['loss', 'val_loss']].plot()
print(("Minimum Validation Loss: {:0.4f}").format(history_df['val_loss'].min()))
빈 그래프가 보이는가? unstandardized 한 데이터의 학습은 보통 실패한다. 설령 수렴한다고 하더라도 그 값이 매우 클 것이다. 이제 이 문제를 batch normalization layer를 추가함으로써 해결해 보자. 총 네개의 batch normalizaion layers를 추가할 것이다. batch normalization layer를 가장 처음에 추가할 것이기 때문에 input shape을 인자로 넘겨주는 것도 잊지 말자.
# YOUR CODE HERE: Add a BatchNormalization layer before each Dense layer
model = keras.Sequential([
layers.BatchNormalization(input_shape=input_shape),
layers.Dense(512, activation='relu'),
layers.BatchNormalization(),
layers.Dense(512, activation='relu'),
layers.BatchNormalization(),
layers.Dense(512, activation='relu'),
layers.BatchNormalization(),
layers.Dense(1),
])자 이제 모델을 학습시킬 차례이다.
model.compile(
optimizer='sgd',
loss='mae',
metrics=['mae'],
)
EPOCHS = 100
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=64,
epochs=EPOCHS,
verbose=0,
)
history_df = pd.DataFrame(history.history)
history_df.loc[0:, ['loss', 'val_loss']].plot()
print(("Minimum Validation Loss: {:0.4f}").format(history_df['val_loss'].min()))
batch normalization을 추가함으로써 문제를 해결했다. data를 network를 통과할때 adaptively scaling함으로써 어려운 datasets를 model이 학습할 수 있도록 해주었다.
'ComputerScience > Machine Learning' 카테고리의 다른 글
| Hands-On-Machine Learning : 29p ~ 66p (0) | 2021.08.11 |
|---|---|
| DeepLearning - 6. Binary Classification (0) | 2021.08.11 |
| DeepLearning - 4. Overfitting and Underfitting (0) | 2021.08.10 |
| DeepLearning - 3. Stochastic Gradient Descent (0) | 2021.08.06 |
| DeepLearning - 2. Deep Neural Networks (0) | 2021.08.04 |



